操作系统笔记(2)-受限直接执行
操作系统笔记(2)-受限直接执行
概念
直接执行: 表示直接在CPU上运行程序受限: 为什么要受限呢 ? 是为了保证操作系统来管理资源, 防止其失去控制权, 操作系统必须以高性能的方式虚拟化CPU, 同时保持对系统的控制, 因此程序的执行需要受限, 具体是受到硬件的限制
如何执行受限制的操作
操作系统引入了两种模式:
用户模式:在此模式下运行的代码会受到限制。例如,在用户模式下运行时,进程不能发出I/O请求内核模式:在此模式下,运行的代码可以做它喜欢的事,包括特权操作,如发出I/O请求和执行特权指令
用户如何执行特权操作
在
用户模式下要执行特权操作,需要使用系统调用,它允许内核小心地向用户程序暴露某些关键功能,例如访问文件系统、创建和销毁进程、与其他进程通信,以及分配更多内存要执行
系统调用,程序必须执行特殊的陷阱(trap)指令, 该指令同时跳入内核并将特权级别提升到内核模式,完成相应工作后,操作系统调用一个特殊的从陷阱返回(return-from-trap)指令,回到用户模式C 库中进行
系统调用的部分是用汇编手工编码的,因为它们需要仔细遵循约定,以便正确处理参数和返回值,以及执行硬件特定的陷阱指令
受限直接运行过程
| 操作系统-启动 (内核模式) | 硬件 | 程序(用户模式) |
|---|---|---|
| 初始化陷阱表 | ||
| 记住系统调用处理程序的地址 | ||
| 在进程列表上创建条目 | ||
| 为程序分配内存 | ||
| 将程序加载到内存中 | ||
| 根据 argv 设置程序栈 | ||
| 用寄存器/程序计数器填充内核栈 | ||
| 从陷阱返回 | ||
| 从内核栈恢复寄存器 | ||
| 转向用户模式 | ||
| 跳到 main | ||
| 运行 main | ||
| 调用系统调用 | ||
| 陷入操作系统 | ||
| 将寄存器保存到内核栈 | ||
| 转向内核模式 | ||
| 跳到陷阱处理程序 | ||
| 处理陷阱 | ||
| 做系统调用的工作 | ||
| 从陷阱返回 | ||
| 从内核栈恢复寄存器 | ||
| 转向用户模式 | ||
| 跳到陷阱之后的程序计数器 | ||
| 从 main 返回 | ||
| 陷入 (通过 exit()) | ||
| 释放进程的内存 | ||
| 将进程从进程列表中清除 |
在进程之间切换
问题
对于
单核系统来说, 如果一个进程在CPU上运行, 这就意味着操作系统没有运行, 那操作系统怎么做事情呢?因此如何重新获得
CPU的控制权以便它可以在进程之间切换变得非常重要
协作方式:等待系统调用
以前采取的一种策略是选择相信用户进程, 运行时间过长的进程被假定会定期放弃
CPU, 以便操作系统可以决定运行其他任务一个问题是, 放弃
CPU需要执行系统调用, 进入内核模式, 将CPU的控制权交给操作系统, 然而如果程序一直无限循环而不进行系统调用, 系统就会卡死以前面对这种问题的解决方法就是
重启
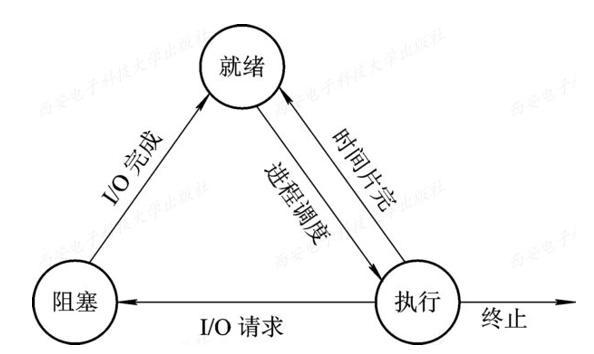
非协作方式:操作系统进行控制
这种方式利用了硬件的
时钟中断, 产生时钟中断时, 当前运行的程序停止, 将状态保存后运行中断处理程序操作系统预先配置好
中断处理程序, 然后当程序启动时开启时钟, 每隔一段时间触发中断处理程序, 将CPU的控制器交给操作系统, 然后操作系统根据调度策略可以决定接下来运行哪个程序如果操作系统决定切换到另一个程序执行, 就会执行一些底层代码, 即所谓的
上下文切换(content switch), 它要做的就是为当前只在执行的程序保存一些寄存器的值, 然后为即将执行的程序恢复一些寄存器的值, 然后切换到另一个程序执行
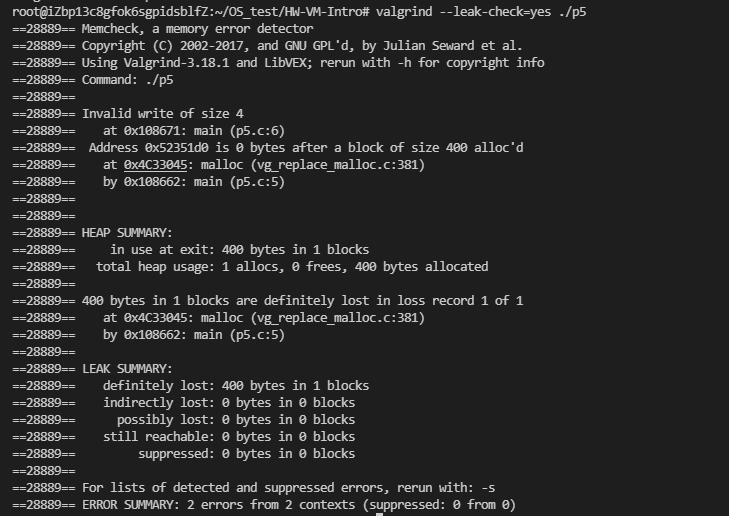
测量作业
- 测试
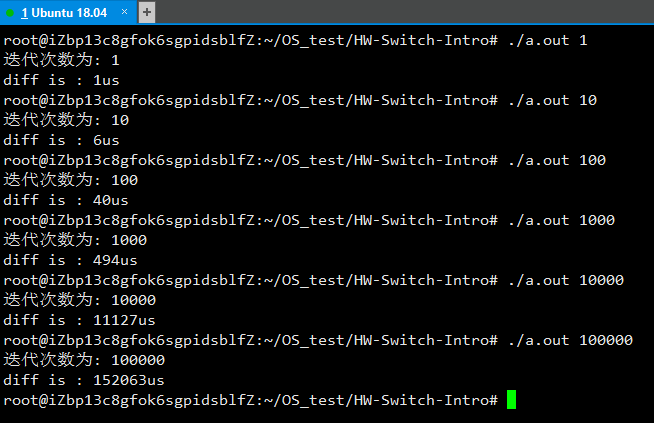
系统调用的执行时间, 使用 C 库的gettimeofday()计算, 以0字节读取为例, 测试机是单核的, 测试代码入下:
#include <stdio.h>
#include <sys/time.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
int main(int argc, char* argv[]) {
if (argc < 2) {
printf("请输入迭代次数\n");
return 0;
}
int cnt = atoi(argv[1]);
printf("迭代次数为: %d\n", cnt);
int fd = open("./p2.txt", O_WRONLY);
struct timeval start, end;
char buf[0];
gettimeofday(&start, NULL);
for (int i = 0; i < cnt; i++) {
// 0 字节读取
write(fd, buf, 0);
}
gettimeofday(&end, NULL);
long int diff = 1000000 * (end.tv_sec - start.tv_sec) + (end.tv_usec - start.tv_usec);
printf("diff is : %ldus\n", diff);
close(fd);
return 0;
}结果验证表明平均调用时间是 1~2us :
- 为进程指定运行在哪个
CPU上, 测试机是双核的, 运行时在另一个窗口通过使用ps -eo pid,args,psr命令查看结果, 测试代码如下:
#define _GNU_SOURCE
#include <stdio.h>
#include <sched.h>
#include <errno.h>
#include <unistd.h>
#include <string.h>
int main(int argc, char* argv[]) {
cpu_set_t mask, get;
int cpus = sysconf(_SC_NPROCESSORS_ONLN);
printf("cpus: %d\n", cpus);
CPU_ZERO(&mask);
CPU_SET(0, &mask); // 将本进程绑定到CPU0上
if (sched_setaffinity(0, sizeof(mask), &mask) == -1) {
printf("Set CPU affinity failure, ERROR: %s\n", strerror(errno));
return -1;
}
while (1) {
sleep(1);
}
return 0;
}结果显示如下:两个 CPU 的编号分别是 0 和 1

- 使用
lmbench工具测试上下文切换的成本
参考官方说明