操作系统笔记(9)-超越物理内存:机制与策略
操作系统笔记(9)-超越物理内存:机制与策略
简介
如果我们需要支持许多同时运行的巨大地址空间,仅仅靠
多级页表是不够的,我们还需要在内存层级上再加一层为了支持更大的地址空间,操作系统需要把当前没有在用的那部分地址空间找个地方存储起来,
硬盘通常能够满足这个需求,多道程序的出现,强烈要求能够换出一些页,因为早期的机器显然不能将所有进程需要的所有页同时放在内存中我们要做的第一件事情就是在硬盘上开辟一部分空间用于
物理页的移入和移出,一般在操作系统中,这样的空间称为交换空间,因为我们将内存中的页交换到其中,并在需要的时候又交换回去
存在位
- 通过之前的机制,我们知道页表项
PTE中含有一些位,其中的存在位的作用就是标识此页是在物理内存还是硬盘中,访问不在物理内存中的页,这种行为通常被称为页错误(page fault)
页错误
不论在哪种系统中,如果页不存在,都由操作系统负责处理
页错误,操作系统的页错误处理程序确定要做什么如果一个页不存在,它已被交换到磁盘,在处理
页错误的时候,操作系统需要将该页交换到内存中,而要找到其在硬盘中的哪个位置,就需要用到PTE中提供的一些信息,找到后将页读取到内存中一般在进行磁盘
I/O操作时,进程会处于阻塞状态,此时可以切换到其它进程运行,这就充分利用了硬件
内存满了怎么办
如果内存已满,我们就只能从物理内存中
换出一些页到硬盘,然后再将需要的页从交换空间换入内存中,选择哪些页被换出或被替换的过程,被称为页交换策略控制流程大致如下:
操作系统为将要换入的页找到一个物理帧
如果没有,等待交换算法运行,从内存中踢出一些页
获得物理帧后,处理程序发出
I/O请求从交换空间读取页操作系统更新页表并重试指令
页替换策略
- 前面说到当内存压力大的时候,我们不得不踢出一些页以供当前运行的进程的内存访问,那么如何踢出页就是需要一些策略,保证踢出的页不会使我们之后频繁地进行
换入换出操作
缓存管理
由于内存只包含系统中所有页的子集,因此可以将其视为系统中虚拟内存页的
缓存(cache),我们的目标是让缓存未命中最少,为了衡量交换策略的效果,提出了一个指标——平均内存访问时间(AMAT),具体来说可以表示为以下的公式:$$AMAT = (P_{Hit} \cdot T_{M}) + (P_{Miss} \cdot T_{D})$$
其中 $P_{Hit}$ 是命中率, $P_{Miss}$ 是未命中率,$T_{M}$ 是访问内存的成本,$T_{D}$ 是访问磁盘的成本
最优替换策略
最优替换策略能够达到总体未命中数量最少,但是它非常
不切实际,它的思想是每次都踢出在最远的将来才会访问的页,因为在引用最远将来会访问的页之前,你肯定会引用其他页虽然它几乎无法实现,但是可以作为一个评判其它策略的指标,如果你的策略效果和最优替换差不多,说明你就可以不用再优化了
FIFO 策略
思路很清晰,在页进入系统时,简单的放入一个队列,当发生替换时,先入的页被踢出,它的优先是实现简单
缺点:
FIFO根本无法确定页的重要性,即使某个页被多次访问,它还是会将其踢出
随机策略
- 随机是很多操作系统策略会考虑的一种方法,因为它能够避免一些边界条件,它的表现完全取决于运行
LRU 策略
前两种策略有一个共同的问题:它可能会踢出一个重要的页,而这个页马上要被引用
为了提高后续的命中率,我们再次通过历史的访问情况作为参考,如果一个页被访问了很多次,也许它不应该被替换,或者越近被访问过的页,也许再次访问的可能性也就更大
基于这种思想:
最不经常使用(Least-Frequently-Used, LFU)策略会替换最不经常使用的页,最少最近使用(Least-Recently-Used, LRU)策略替换最近最少使用的页面
练习:C 语言模拟 LRU
LRU算法的基本流程是,首先给出想要访问的物理页地址,如果它不在缓存中,就需要将在交换空间中找到它并加入缓存,为了实现LRU,缓存被设计为一种双向链表,从链表头到链表尾访问间隔递增,即链表尾的页是在换出时优先考虑的页,每次换入一页或访问已在缓存中的页,就将其插入双向链表的头部优化 :如果每次查找是否在缓存中有需要的页时都把链表遍历一遍,就太慢了,当缓存较大时遍历的开销会很大,因此使用
散列表建立地址到链表结点的映射,同时,当换出页时,为了减少开销,我们实现时没有删除这个结点,而是更改这个结点的相关数据,再把它当成新结点用为了更直观地理解实现,这里
散列表就通过数组下标来映射,规定用proc来标识不同进程的页,值范围限制在0~65535,为了双向链表更好实现,使用了虚拟头尾结点
代码实现如下 :
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define PROCMAX_SIZE 65536
typedef struct node {
int proc;
// other message...
struct node *prev, *next;
} node;
typedef struct {
int capacity; // 缓存容量
int used; // 已使用大小
node **mp; // 散列表, 建立 proc -> node* 的映射
node *head, *tail; // 使用头尾结点标识双向链表
} LRUCache;
// 初始化指定容量
LRUCache* LRUCacheCreate(int capacity_) {
LRUCache *lru = (LRUCache*)malloc(sizeof(LRUCache));
lru->capacity = capacity_;
lru->used = 0;
lru->mp = (node**)calloc(PROCMAX_SIZE, sizeof(node*)); // calloc 自带初始化
lru->head = (node*)malloc(sizeof(node));
lru->tail = (node*)malloc(sizeof(node));
lru->head->next = lru->tail, lru->head->prev = NULL;
lru->tail->prev = lru->head, lru->tail->next = NULL;
return lru;
}
void LRUCachePrint(LRUCache* lru) {
printf("LRUCache : [");
for (node *p = lru->head->next; p != lru->tail; p = p->next) {
printf(" %d", p->proc);
}
puts(" ]");
}
// 返回是否命中
bool LRUCacheVisit(LRUCache* lru, int proc) {
printf("Visite : %d ", proc);
if (lru->mp[proc] != NULL) { // 缓存中存在
printf("Cache Hit -> "); // 缓存命中
// 将结点插入到链表头部
node *p = lru->mp[proc];
p->next->prev = p->prev;
p->prev->next = p->next;
p->next = lru->head->next;
lru->head->next->prev = p;
p->prev = lru->head;
lru->head->next = p;
LRUCachePrint(lru); // 打印一下缓存
return true;
}
else {
printf("Cache Miss -> ");
if (lru->used == lru->capacity) { // 缓存已满
node *p = lru->tail->prev; // 取出要换出的结点
// 小优化, 把这个结点重新利用
lru->mp[p->proc] = NULL;
p->proc = proc;
lru->mp[proc] = p;
lru->tail->prev = p->prev;
p->prev->next = lru->tail;
p->next = lru->head->next;
lru->head->next->prev = p;
p->prev = lru->head;
lru->head->next = p;
}
else {
++lru->used;
node *p = (node*)malloc(sizeof(node));
p->proc = proc;
p->next = lru->head->next;
lru->head->next->prev = p;
p->prev = lru->head;
lru->head->next = p;
lru->mp[proc] = p;
}
LRUCachePrint(lru); // 打印一下缓存
}
return false;
}
void LRUCacheFree(LRUCache* lru) {
node *cur = lru->head;
while (cur != NULL) {
node *next = cur->next;
free(cur);
cur = next;
}
free(lru->mp);
free(lru);
}
int main(int argc, char* argv[]) {
int n, m, cap;
scanf("%d %d", &cap, &n);
printf("请依次输入请求序列 :\n");
int a[100];
for (int i = 0; i < n; i++) {
scanf("%d", &a[i]);
}
LRUCache* lru = LRUCacheCreate(cap);
m = 0; // 命中次数
for (int i = 0; i < n; i++) {
if (LRUCacheVisit(lru, a[i])) {
++m;
}
}
printf("命中次数为 %d\n命中率为 : %.2lf\n", m, (float)m / n);
LRUCacheFree(lru);
return 0;
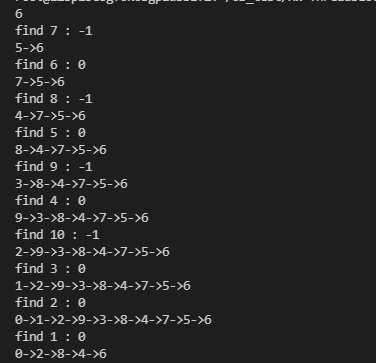
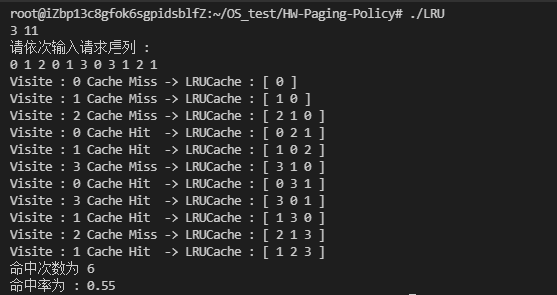
}测试序列 :假设 LRUCache 大小为 3 ,测试一个长度为 11 的访问序列 0, 1, 2, 0, 1, 3, 0, 3, 1, 2, 1
测试结果 :
缺点
对于某些特定的访问序列,
LRU和FIFO的命中率特别糟糕,比如对于一个大小为3的LRU缓存,0 1 2 3 4 0 1 2 3 4 ...这种循环序列会导致0的命中率!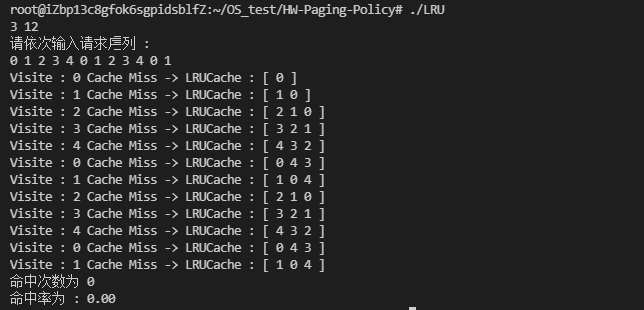
小结
现代系统增加了对时钟等简单
LRU近似值的一些调整,如扫描抗性算法,它试图避免LRU的最坏情况行为过度分页的最佳解决方案往往很简单:
购买更多的内存