操作系统笔记(11)-锁
操作系统笔记(11)-锁
简介
- 上一个笔记介绍了
POSIX提供的互斥锁API,我们知道了在进入临界区前加锁,能够保证临界区能够像单条原子指令一样执行
评价锁
评价一个锁主要从三个方面来看:
提供互斥 :锁需要提供的最基本功能
公平性 :确保每一个竞争线程有公平的机会获得锁
性能 :使用锁之后的性能如何(在各种环境下)
实现一个锁
测试并设置指令(原子交换)
早期由硬件支持的
原子交换指令,即测试并设置(test-and-set),它的逻辑实现如下:// 硬件保证此操作是原子的, x86 为 xchg 指令 int TestAndSet(int *old_ptr, int new_value) { int old = *old_ptr; *old_ptr = new_value; return old; }实现一个
自旋锁typedef struct lock_t { int flag; } lock_t; void init(lock_t *lock) { lock->flag = 0; } void lock(lock_t *lock) { while (TestAndSet(&lock->flag, 1)) { // spin-wait } } void unlock(lock_t *lock) { lock->flag = 0; }评价:对于单
CPU来说自旋锁很浪费CPU周期,并且它不提供任何公平性保证,可能会导致饿死,即一直自旋。而在多CPU上,自旋锁性能不错
比较并交换
某些系统还提供了另一个硬件原语,即
比较并交换指令(compare-and-exchange),它的逻辑实现如下:int CompareAndSwap(int *ptr,int expected, int new_value) { int actual = *ptr; if (actual == expected) *ptr = new_value; return actual; }要实现如上的
自旋锁,可以使用此指令void lock(lock_t *lock) { while (CompareAndSwap(&lock->flag, 0, 1)) { // spin-wait } }
获取并增加指令
最后一个硬件原语是
获取并增加(fetch-and-add)指令,它能原子地返回特定地址的旧值,并且让该值自增一,其逻辑实现如下:int FetchAndAdd(int *ptr) { int old = *ptr; *ptr = old + 1; return old; }利用此指令来实现
自旋锁typedef struct lock_t { int ticket; int turn; } lock_t; void lock_init(lock_t *lock) { lock->ticket = 0; lock->turn = 0; } void lock(lock_t *lock) { int myturn = FetchAndAdd(&lock->ticket); while (lock->turn != myturn) { // spin } } void unlock(lock_t *lock) { FetchAndAdd(&lock->turn); }评价:不同于之前的方法,本方法能够保证所有线程都能够抢到锁,只要一个线程获得了
ticket值,它最终会被调度
自旋过多怎么办
- 一个自旋的线程会做无谓的循环而浪费时间片,因此只有硬件支持是不够的,还需要操作系统支持
线程主动让出 CPU
操作系统提供一个
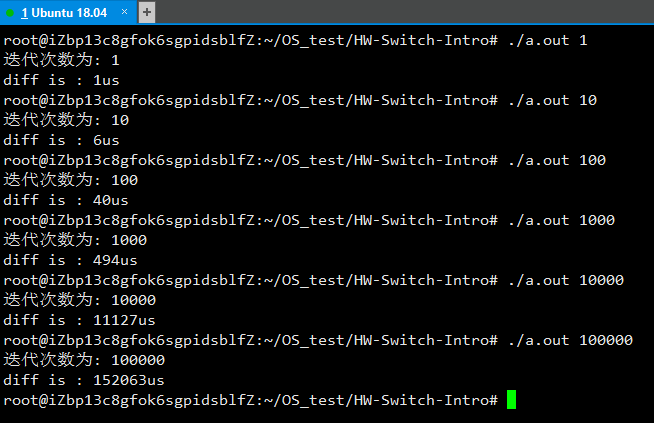
yield()调用, 可以让自旋线程主动让出CPU,让获得锁的线程获得更多的时间片yield()系统调用能够让运行态变为就绪态,从而允许其他线程运行void lock(lock_t *lock) { while (TestAndSet(&lock->flag, 1)) { yield(); } }缺点:假设在单核机器上有
100个线程竞争同一个锁,这样就算其他99个线程都调用yield(),这样会导致这些线程一直处于让出状态
使用队列:休眠替代资源
假设操作系统提供两个系统调用,
park()可以使当前线程休眠,unpark(threadID)可以唤醒指定 ID 的线程typedef struct lock_t { int flag; int guard; queue_t *q; } lock_t; void lock_init(lock_t *m) { m->flag = 0; m->guard = 0; queue_init(m->q); } void lock(lock_t *m) { while (TestAndSet(&m->guard, 1) == 1) ; // acquire guard by spinning if (m->flag == 0) { m->flag = 1; // lock is acquired m->guard = 0; } else { queue_add(m->q, gettid()); m->guard = 0; park(); } } void unlock(lock_t *m) { while (TestAndSet(&m->guard, 1) == 1) ; if (queue_empty(m->q)) { m->flag = 0; // let go of lock } else { unpark(queue_remove(m->q)); // hold lock } m->guard = 0; }评价:通过队列来控制谁会获得锁,避免饿死。但是这个方法并没有完全避免自旋等待,并且如果在
park()之前切换到另一个线程,可能导致线程一直睡眠下去,通过增加第三个系统调用setpark()来解决,表面自己马上要park(),如果刚好另外一个线程被调度,并且调用了unpark(),那么后续的park()调用就会直接返回,而不是一直睡眠queue_add(m->q, gettid()); setpark(); m->guard = 0;
基于锁的并发数据结构
- 通过锁可以使数据结构线程安全,下面练习实现一些常见的数据结构的线程安全版
并发链表
#ifndef _LIST_H_
#define _LIST_H_
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
typedef struct node_t {
int key;
struct node_t *next;
} node_t;
typedef struct list_t {
node_t *head;
pthread_mutex_t lock;
} list_t;
void List_Init(list_t *L) {
L->head = NULL;
pthread_mutex_init(&L->lock, NULL);
}
void List_Insert(list_t *L, int key) {
node_t *p = malloc(sizeof(node_t));
if (p == NULL) {
perror("malloc");
return;
}
p->key = key;
pthread_mutex_lock(&L->lock);
p->next = L->head;
L->head = p;
pthread_mutex_unlock(&L->lock);
}
void List_Delete(list_t *L, int key) {
pthread_mutex_lock(&L->lock);
node_t *p = L->head;
if (p == NULL) {
}
else if (p->key == key) {
L->head = p->next;
free(p);
}
else {
while (p->next) {
if (p->next->key == key) {
node_t *tmp = p->next;
p->next = tmp->next;
free(tmp);
break;
}
p = p->next;
}
}
pthread_mutex_unlock(&L->lock);
}
int List_Lookup(list_t *L, int key) {
int rv = -1;
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr) {
if (curr->key == key) {
rv = 0;
break;
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return rv;
}
void List_Print(list_t *L) {
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr) {
printf("%d", curr->key);
curr = curr->next;
if (curr) printf("->");
else printf("\n");
}
pthread_mutex_unlock(&L->lock);
}
void List_Free(list_t *L) {
node_t *curr = L->head;
while (curr) {
node_t *tmp = curr;
curr = curr->next;
free(tmp);
}
pthread_mutex_destroy(&L->lock);
free(L);
}
#endif测试
#include "list.h"
#define ThreadNum 10
int keys[ThreadNum];
list_t *L;
void* work(void *arg) {
int key = *(int*)arg;
List_Insert(L, key);
List_Print(L);
printf("find %d : %d\n", key + 1, List_Lookup(L, key + 1));
return NULL;
}
int main(int argc, char* argv[]) {
pthread_t threads[ThreadNum];
L = malloc(sizeof(list_t));
List_Init(L);
for (int i = 0; i < ThreadNum; i++) {
keys[i] = i;
pthread_create(&threads[i], NULL, work, (void*)&keys[i]);
}
for (int i = 0; i < ThreadNum; i++) {
if (i & 1) List_Delete(L, i);
pthread_join(threads[i], NULL);
}
List_Print(L);
List_Free(L);
return 0;
}
/* output:
6
find 7 : -1
5->6
find 6 : 0
7->5->6
find 8 : -1
4->7->5->6
find 5 : 0
8->4->7->5->6
find 9 : -1
3->8->4->7->5->6
find 4 : 0
9->3->8->4->7->5->6
find 10 : -1
2->9->3->8->4->7->5->6
find 3 : 0
1->2->9->3->8->4->7->5->6
find 2 : 0
0->1->2->9->3->8->4->7->5->6
find 1 : 0
0->2->8->4->6
*/并发队列
#ifndef _QUEUE_H
#define _QUEUE_H
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <stdbool.h>
typedef struct node_t {
int value;
struct node_t *next;
} node_t;
typedef struct queue_t {
node_t *head;
node_t *tail;
pthread_mutex_t headLock;
pthread_mutex_t tailLock;
} queue_t;
void Queue_Init(queue_t *q) {
node_t *tmp = malloc(sizeof(node_t));
tmp->next = NULL;
q->head = q->tail = tmp;
pthread_mutex_init(&q->headLock, NULL);
pthread_mutex_init(&q->tailLock, NULL);
}
void Queue_Enqueue(queue_t *q, int value) {
node_t *tmp = malloc(sizeof(node_t));
tmp->value = value;
tmp->next = NULL;
pthread_mutex_lock(&q->tailLock);
q->tail->next = tmp;
q->tail = tmp;
pthread_mutex_unlock(&q->tailLock);
}
int Queue_Dequeue(queue_t *q, int *value) {
pthread_mutex_lock(&q->headLock);
node_t *tmp = q->head;
node_t *newHead = q->head->next;
if (newHead == NULL) {
pthread_mutex_unlock(&q->headLock);
return -1;
}
*value = newHead->value;
q->head = newHead;
pthread_mutex_unlock(&q->headLock);
free(tmp);
return 0;
}
bool Queue_Empty(queue_t *q) {
bool ret = false;
pthread_mutex_lock(&q->headLock);
pthread_mutex_lock(&q->tailLock);
if (!q->head->next) {
ret = true;
}
pthread_mutex_unlock(&q->tailLock);
pthread_mutex_unlock(&q->headLock);
return ret;
}
void Queue_Free(queue_t *q) {
pthread_mutex_destroy(&q->headLock);
pthread_mutex_destroy(&q->tailLock);
node_t *curr = q->head;
while (curr) {
node_t *tmp = curr;
curr = tmp->next;
free(tmp);
}
free(q);
}
#endif测试
#include "queue.h"
#define ThreadNums 10
int args[ThreadNums];
queue_t *q;
void* run(void *arg) {
Queue_Enqueue(q, *(int*)arg);
return NULL;
}
int main(int argc, char* argv[]) {
q = malloc(sizeof(queue_t));
Queue_Init(q);
pthread_t threads[ThreadNums];
for (int i = 0; i < ThreadNums; i++) {
args[i] = i;
pthread_create(&threads[i], NULL, run, (void*)&args[i]);
}
for (int i = 0; i < ThreadNums; i++) {
pthread_join(threads[i], NULL);
}
int value;
while (!Queue_Empty(q)) {
Queue_Dequeue(q, &value);
printf("%d\n", value);
}
Queue_Free(q);
return 0;
}
/* output:
6
7
5
8
9
4
3
2
1
0
*/并发散列表
#ifndef _HASH_H
#define _HASH_H
#include "list.h"
#include <math.h>
#define BUCKETS (13333)
typedef struct hash_t {
list_t lists[BUCKETS];
} hash_t;
void Hash_Init(hash_t *H) {
for (int i = 0; i < BUCKETS; i++) {
List_Init(&H->lists[i]);
}
}
void Hash_Insert(hash_t *H, int key) {
int bucket = abs(key) % BUCKETS;
List_Insert(&H->lists[bucket], key);
}
int Hash_Lookup(hash_t *H, int key) {
int bucket = abs(key) % BUCKETS;
return List_Lookup(&H->lists[bucket], key);
}
#endif测试
#include "hash.h"
#define ThreadNums 10
int args[ThreadNums];
hash_t *H;
void* run(void *arg) {
Hash_Insert(H, *(int*)arg);
return NULL;
}
int main(int argc, char* argv[]) {
H = malloc(sizeof(hash_t));
Hash_Init(H);
pthread_t threads[ThreadNums];
for (int i = 0; i < ThreadNums; i++) {
args[i] = rand();
printf("%d ", args[i]);
pthread_create(&threads[i], NULL, run, (void*)&args[i]);
}
puts("");
for (int i = 0; i < ThreadNums; i++) {
pthread_join(threads[i], NULL);
}
for (int i = 0; i < ThreadNums; i++) {
printf("%d\n", Hash_Lookup(H, args[i]));
}
return 0;
}
/* output:
1804289383 846930886 1681692777 1714636915 1957747793 424238335 719885386 1649760492 596516649 1189641421
0
0
0
0
0
0
0
0
0
0
*/小结
增加并发
不一定能提高性能,有性能问题的时候再做优化,避免不成熟的优化让整个应用的一小部分变快,却没有提高整体性能,其实没有价值