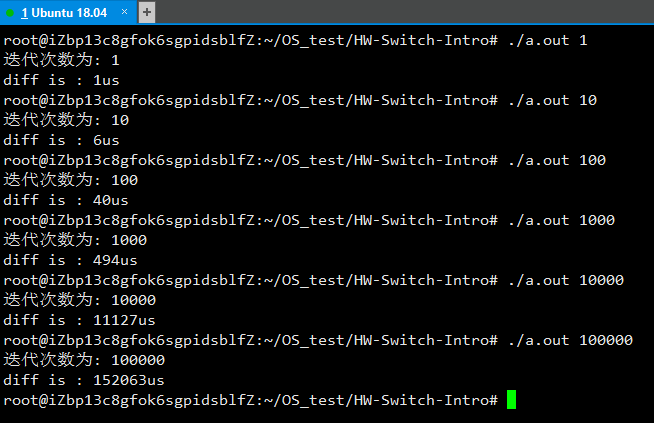
操作系统笔记(14)-常见并发问题
操作系统笔记(14)-常见并发问题
简介
- 常见的并发程序缺陷主要有两种:
非死锁缺陷和死锁缺陷
非死锁缺陷
- 非死锁缺陷主要又分为两种:
违反原子性缺陷和错误顺序缺陷
违反原子性缺陷
- 违反原子性的定义是:违反了多次内存访问中预期的可串行性(即代码段本意是原子的,但是在执行中并没有强制实现原子性)
T0:
if (ptr != NULL) {
doSomething(ptr);
}
T1:
ptr = NULL;- 若线程
T0正要执行doSomething之前切换到T1执行,将ptr置为NULL,再切回T0会导致程序崩溃
解决方法 : 在代码前后添加互斥锁,避免线程切换
违反顺序缺陷
- 违反顺序的定义是:两个内存访问的预期顺序打破了(即 A 应该在 B 之前执行,但是实际运行中却不是这个顺序)
T0:
void init() {
ptr = CreatePtr(mMain, ...);
}
T1:
void mMain(...) {
ret = ptr->ret;
}- 若线程
T1先执行了,就可能因为空指针崩溃
解决方法 : 使用条件变量使线程 T1 总是等到 T0 完成任务后再继续执行
死锁缺陷
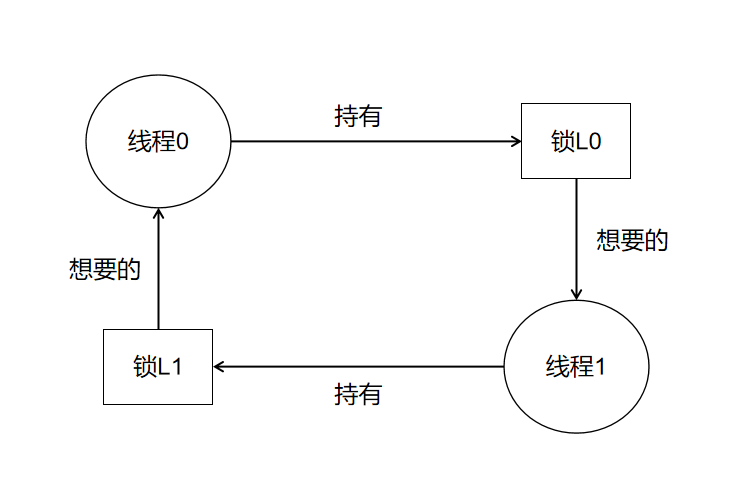
死锁(deadlock)是一种在许多复杂并发系统中出现的经典问题,例如当线程T0持有锁L0,正在等待另外一个锁L1,而线程T1持有锁L1,正在等待锁L0,这种相互等待导致死锁
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
pthread_mutex_t m1 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t m2 = PTHREAD_MUTEX_INITIALIZER;
void* worker(void* arg) {
if ((long long) arg == 0) {
pthread_mutex_lock(&m1);
sleep(1); // 保证 T1 拿到 m2
pthread_mutex_lock(&m2);
pthread_mutex_unlock(&m2);
pthread_mutex_unlock(&m1);
} else {
pthread_mutex_lock(&m2);
sleep(1); // 保证 T0 拿到 m1
pthread_mutex_lock(&m1);
pthread_mutex_unlock(&m1);
pthread_mutex_unlock(&m2);
}
return NULL;
}
int main(int argc, char *argv[]) {
pthread_t p1, p2;
pthread_create(&p1, NULL, worker, (void *) (long long) 0);
pthread_create(&p2, NULL, worker, (void *) (long long) 1);
pthread_join(p1, NULL);
pthread_join(p2, NULL);
return 0;
}产生死锁的条件
互斥 :线程对于需要的资源进行
互斥的访问持有并等待 :线程持有了资源,同时又在等待其他资源
非抢占 :线程获得的资源,不能被抢占
循环等待 :线程之间存在一个环路,环路上每个线程都额外持有一个资源,而这个资源又是下一个线程要申请的
死锁预防
- 针对产生死锁的
4个条件,只要使其中任意一个条件不满足即可解决死锁的问题
循环等待
- 一种方式是获取锁是的顺序规定为一致的,这样就可以避免死锁,但是在复杂的系统中很难做到,因此也有为锁划分优先级的做法
持有并等待
- 可以通过原子地抢锁在避免,也就是添加一个
全局的锁来避免
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
pthread_mutex_t m1 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t m2 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t global_m = PTHREAD_MUTEX_INITIALIZER;
void* worker(void* arg) {
if ((long long) arg == 0) {
pthread_mutex_lock(&global_m);
pthread_mutex_lock(&m1);
sleep(1); // 保证 T1 拿到 m2
pthread_mutex_lock(&m2);
pthread_mutex_unlock(&m2);
pthread_mutex_unlock(&m1);
pthread_mutex_unlock(&global_m);
} else {
pthread_mutex_lock(&global_m);
pthread_mutex_lock(&m2);
sleep(1); // 保证 T0 拿到 m1
pthread_mutex_lock(&m1);
pthread_mutex_unlock(&m1);
pthread_mutex_unlock(&m2);
pthread_mutex_unlock(&global_m);
}
return NULL;
}
int main(int argc, char *argv[]) {
pthread_t p1, p2;
pthread_create(&p1, NULL, worker, (void *) (long long) 0);
pthread_create(&p2, NULL, worker, (void *) (long long) 1);
pthread_join(p1, NULL);
pthread_join(p2, NULL);
return 0;
}缺点 : 不适用于 封装 ,因为这个方案需要我们准确地知道要抢哪些锁,并且提前抢到这些锁,同时可能 降低了并发
非抢占
利用操作系统线程库提供的接口来避免
非抢占的情况,例如trylock()函数会尝试获得锁,或者返回-1,这样就不会一直阻塞线程了可以通过这种方式来实现无死锁的加锁方式
// T0
top:
lock(L0);
if (trylock(L1) == -1) {
unlock(L0);
goto top;
}
// T1
top:
lock(L1);
if (trylock(L0) == -1) {
unlock(L1);
goto top;
}缺点 : 使用这种方式会引来一个新的问题—— 活锁 ,系统一直循环运行一段代码,解决方法就是在循环结束的时候先随机等待一个时间,然后再重复整个动作,这样可以降低线程之间的重复互相干扰
互斥
- 利用各种
无等待的数据结构,它们通过强大的硬件指令,实现了不需要锁的原子功能
死锁避免
通过调度
- 根据不同线程对锁的需求不同,安排线程在不同的
CPU上运行,使需求相同锁的线程不太同一段时间执行,但是这样需要我们知道全局的信息,并且有可能会因为调度而延长了总的执行时间
检查和恢复
- 最后一种常用的策略就是
允许死锁偶尔发生,检查到死锁时再采取行动,很多数据库系统使用了死锁检测和恢复技术,死锁检测器会定期运行,通过构建资源图来检查循环;当死锁发生时,系统需要重启
进阶:基于事件的并发
某些类型的网络服务器常常采用另一种并发方式,称为
基于事件的并发,它的想法就是我们等待某事发生,当它发生时,检查事件类型,然后做相应的工作while (1) { events = getEvents(); for (e in events) processEvent(e); }而要接收这些事件,我们需要利用操作系统提供的系统调用,如
select()、poll()或 Linux 提供的epoll(), 它们的接口描述如下
select 系统调用
select系统调用的用途是:在 一段指定时间内 , 监听 用户感兴趣的文件描述符上的 可读 、可写 和 异常 等事件#include <sys/select.h> int select(int nfds, fd_set* readfds, fd_set* writefds, fd_set* exceptfds, struct timeval* timeout); // fd_set 结构体定义如下 typedef struct { __fd_mask fds_bits[__FD_SETSIZE / __NFDBITS]; } fd_set; // fd_set 结构体仅包含一个整型数组,该数据的每个元素的每一位标记一个文件描述符 // 能容纳的文件描述符数量由 FD_SETSIZE 指定,这就限制了 select 能同时处理的文件描述符的数量 /* 由于位操作过于繁琐, 我们应该使用下面的一系列宏来访问 fd_set 结构体中的位 */ FD_ZERO(fd_set* fdset); /* 清除 fdset 的所有位 */ FD_SET(int fd, fd_set* fdset); /* 设置 fdset 的位fd */ FD_CLR(int fd, fd_set* fdset); /* 清除 fdset 的位fd */ int FD_ISSET(int fd, fd_set* fdset);/* 测试 fdset 的位 fd s是否被设置 */nfds参数指定被监听的文件描述符的总数,通常被设置为select监听的所有文件描述符中的最大值加1,因为文件描述符是从0开始计数的
readfds 、writefds 和 exceptfds 参数分别指向可读、可写和异常等事件对应的文件描述符集合,select 调用返回时,内核将修改它们来通知应用程序哪些文件描述符已经就绪
timeout 参数用来设置 select 函数的超时时间,它是一个 timeval 结构类型的指针,采用指针参数是因为内核将修改它以告诉应用程序 select 等待了多久。不过我们不能完全信任 select 调用返回后的 timeout 值,比如调用失败时 timeout 值是不确定的,timeval 结构体的定义如下:
struct timeval {
long tv_sec; /* 秒数 */
long tv_usec; /* 微妙数 */
};如果给 timeout 传递 NULL,则 select 将一直阻塞,直到某个文件描述符就绪
select 成功时返回就绪(可读、可写和异常)文件描述符的总数。如果在超时时间内没有任何文件描述符就绪,select 将返回0。select 失败时返回-1并设置 errno。如果在 select 等待期间,程序接收到信号,则 select 立即返回 -1 ,并设置 errno 为 EINTR
使用 select()
// 同时接收普通数据和带外数据
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/select.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
int main(int argc, char* argv[]) {
if (argc <= 2) {
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
int connfd = accept(listenfd, NULL, NULL);
if (connfd < 0) {
printf("errno is: %d\n", errno);
close(listenfd);
close(listenfd);
return 1;
}
char buf[1024];
fd_set read_fds;
fd_set exception_fds;
FD_ZERO(&read_fds);
FD_ZERO(&exception_fds);
while (1) {
memset(buf, '\0', sizeof(buf));
FD_SET(connfd, &read_fds);
FD_SET(connfd, &exception_fds);
ret = select(connfd + 1, &read_fds, NULL, &exception_fds, NULL);
if (ret < 0) {
puts("selection failure");
break;
}
if (FD_ISSET(connfd, &read_fds)) {
ret = recv(connfd, buf, sizeof(buf) - 1, 0);
if (ret <= 0) {
break;
}
printf("get %d bytes of normal data: %s\n", ret, buf);
}
else if (FD_ISSET(connfd, &exception_fds)) {
ret = recv(connfd, buf, sizeof(buf) - 1, MSG_OOB);
if (ret <= 0) {
break;
}
printf("get %d bytes of oob data: %s\n", ret, buf);
}
}
close(connfd);
close(listenfd);
return 0;
}poll 系统调用
poll系统调用和select类似,也是在指定时间内轮询一定数量的文件描述符,以测试其中是否有就绪者
#include <poll.h>
int poll(struct pollfd* fds, nfds_t nfds, int timeout);fds 参数是一个 pollfd 结构类型的数组,它定义所有我们感兴趣的文件描述符上发生的可读、可写和异常等事件。pollfd 结构体的定义如下:
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 注册的事件 */
short revents; /* 实际发生的事件, 由内核填充 */
};其中, fd 成员指定文件描述符;events 成员告诉 poll 监听 fd 上的哪些事件,它是一系列事件的按位或;revents 成员则由内核修改,以通知应用程序 fd 上实际发生了哪些事件,poll 事件类型如下:
- POLLIN : 数据可读(包括普通数据和优先数据)
- POLLRDNORM:普通数据可读
- POLLRDBAND:优先级带数据可读(Linux不支持)
- POLLRPI:高优先级数据可读,比如 TCP 带外数据
- POLLOUT:数据可写(包括普通数据和优先数据)
- POLLWRNORM:普通数据可写
- POLLWRBAND:优先级带数据可写
- POLLRDHUP:TCP 连接被对方关闭,或者对方关闭了写操作(它由GNU引入)
- POLLERR :错误
- POLLHUP:挂起
- POLLNVAL:文件描述符没有打开
自 Linux 内核 2.6.17 开始, GNU 为 poll 系统调用增加了一个 POLLRDHUP 事件,它在 socket 上接收到对方关闭连接的请求之后出发。但使用时我们需要在代码最开始处定义 _GNU_SOURCE
nfds 参数指定被监听事件集合 fds 的大小,其类型 nfds_t 的定义如下:
typedef unsigned long int nfds_t;timeout 参数指定 poll 的超时值,单位是毫秒。当 timeout 为 -1 时,poll 调用将永远阻塞,直到某个事件发生;当 timeout 为 0 时,poll 调用将立即返回
epoll 系统调用
epoll是 Linux 系统提供的一个系统调用,它的功能比较多,可以通过文档来了解关于它的更多细节
异步 I/O
有时候事件会请求某些资源,可能需要我们阻塞
I/O去访问磁盘,例如open()或read(),一般我们可以利用多线程来解决这个问题,即开一个线程来处理,但是,使用基于事件的方法时,没有其他线程可以运行为了解决这个问题,操作系统提供了
异步I/O接口,它们使应用程序能够发出I/O请求,并在I/O完成之前立即将控制权返回给调用者,并发送一个中断信号,这样就能够及时处理异步请求
状态管理
- 使用
异步I/O的方式需要解决状态管理的问题,例如下任务
int rc = read(fd, buffer, size);
rc = write(sd, buffer, size);- 如果利用
异步I/O,返回一个rc时,我们需要确定它对应的sd才能继续工作,因此需要我们对其进行管理,这里我们可以利用散列表记录rc到sd的映射来管理