
网络编程笔记
网络编程
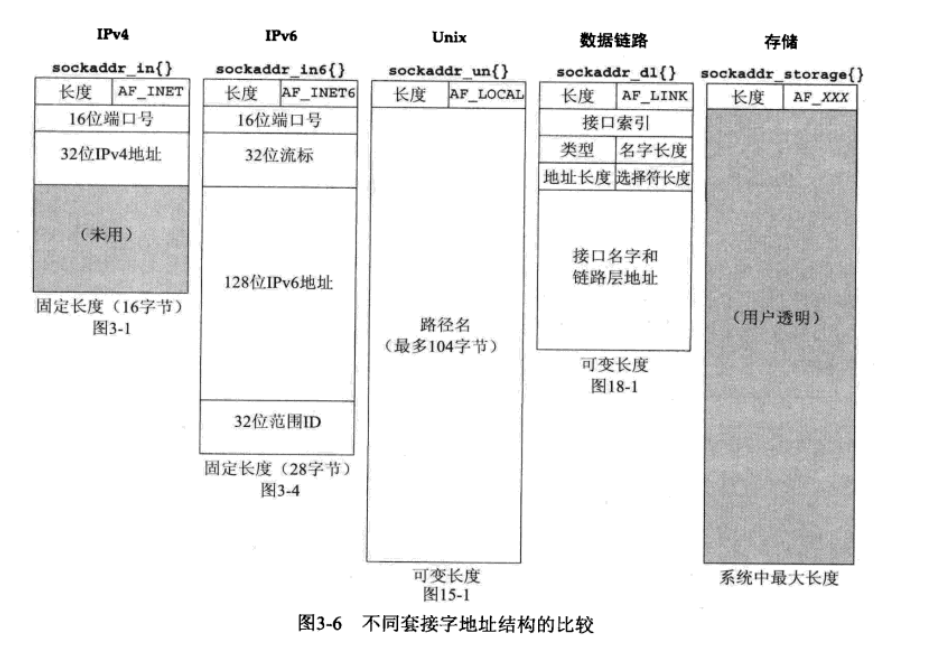
IPv4 套接字地址结构
它以 sockaddr_in 命名,定义在 <netinet/in.h> 头文件中,POSIX 定义如下:
struct in_addr {
in_addr_t s_addr; /* 32-bit IPv4 address */
};
struct sockaddr_in {
uint8_t sin_len;
sa_family_t sin_family; /* AF_INET */
in_port_t sin_port; /* 16-bit TCP or UDP port number */
struct in_addr sin_addr; /* 32-bit IPv4 address */
char sin_zero[8]; /* unused */
};POSIX 规范只需要这个结构中的3个字段:sin_family 、sin_addr 和 sin_port 。

sin_zero字段未曾使用,不过在填写这种套接字地址结构时,我们总是把该字段置为 0。按照惯例,我们总是在填写前把整个结构置为 0,而不是单单把sin_zero字段置为 0。(尽管多数使用该结构的情况不要求这一字段为0,但是当捆绑一个非通配的 IPv4 地址时,该字段必须为 0)- 套接字地址结构仅在给定主机上使用:虽然结构中的某些字段(例如 IP 地址和端口号)用在不同主机之间的通信中,但是结构本身并不在主机之间传递
通用套接字地址结构
当作为一个参数传递进任何套接字函数时,套接字地址结构总是以引用形式(也就是以指向该结构的指针)来传递。然而以这样的指针作为参数之一的任何套接字函数必须处理来自所支持的任何协议族的套接字地址
在如何声明所传递指针的数据类型上存在一个问题。有了 ANSI C 后解决办法很简单:void* 是通用的指针类型。然而套接字函数是在 ANSI C之前定义的,在1982年采取的办法是在 <sys/socket.h> 头文件中定义一个通用的套接字地址结构
struct sockaddr {
uint8_t sa_len;
sa_family_t sa_family; /* address family : AF_xxx value */
char sa_data[14]; /* protocol-specific address */
}; 于是套接字函数被定义为以指向某个通用套接字地址结构的一个指针作为其参数之一,正如bind函数的ANSI C函数原型所示:
int bind(int, struct sockaddr *, socklen_t); 这就要求对这些函数的任何调用都必须要将指向特定于协议的套接字地址结构的指针进行类型强制转换,变成指向某个通用套接字地址结构的指针,例如:
struct sockaddr_in serv;
bind(sockfd, (struct sockaddr *)&serv, sizeof(serv)); 如果我们省略了其中的类型强制类型转换部分并假设系统的头文件中有 bind 函数的一个ANSI C原型,那么 C 编译器就会产生警告:把不兼容的指针类型传递给 bind 函数的第二个参数
从内核的角度看,使用指向通用套接字地址结构的指针另有原因:内核必须取调用者的指针,把它类型强制转换为 struct sockaddr * 类型,然后检查其中 sa_family 字段的值来确定这个结构的真实类型。然而从应用程序开发人员的角度看,要是 void * 这个指针类型可用那就更简单了,因为无须显式进行类型强制转换
IPv6 套接字地址结构
IPv6套接字地址结构在 <netinet/in.h> 头文件中定义
struct in6_addr {
uint8_t s6_addr[16];
};
#define SIN6_LEN /* required for complie-time tests */
struct sockaddr_in6 {
uint8_t sin6_len; /* length of this struct (28) */
sa_family_t sin6_famliy; /* AF_INET6 */
in_port_t sin6_port; /* transport layer port# */
uint32_t sin6_flowinfo; /* flow information, undefined */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* set of interfaces for a scope */
};- 如果系统支持套接字地址结构中的长度字段,那么
SIN6_LEN常值必须定义 - IPv6 的地址族是
AF_INET6,而 IPv4 的地址族AF_INET - 结构中字段的先后顺序做过编排,使得如果
sockaddr_in6结构本身是64位对齐的,那么128位的sin6_addr字段也是64位对齐的。在一些64位处理机上,如果64位数据存储在某个64位边界位置,那么对它的访问将得到优化处理 sin6_flowinfo字段分成两个字段:- 低序20位是流标(flow label)
- 高序12位保留
新的通用套接字地址结构
作为 IPv6 套接字 API 的一部分而定义的新的通用套接字地址结构克服了现有 struct sockaddr 的一些缺点。不像 struct sockaddr ,新的 struct sockaddr_storage 足以容纳系统所支持的任何套接字地址结构。sockaddr_storage 结构在 <netinet/in.h> 头文件中定义:
struct sockaddr_storage {
uint8_t ss_len;
sa_family_t ss_family;
}; sockaddr_storage 类型提供的通用套接字地址结构相比 sockaddr 存在以下两点差别:
(1) 如果系统支持的任何套接字地址结构有对齐需要,那么 sockaddr_storage 能够满足最苛刻的对齐要求
(2) sockaddr_storage 足够大,能够容纳系统支持的任何套接字地址结构(注意:除了 ss_family 和 ss_len 外,sockaddr_storage 结构中的其他字段对用户来说是透明的。sockaddr_storage 结构必须类型强制转换成或复制到适合于 ss_family 字段所给出的地址类型的套接字地址结构中,才能访问其他字段)
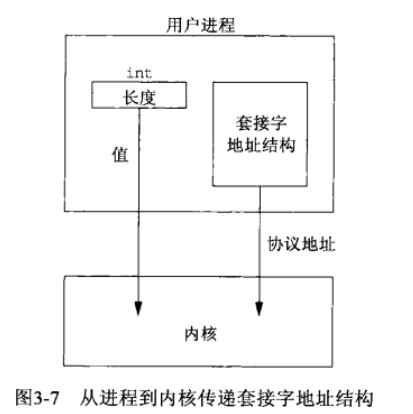
值-结果参数
(1)从进程到内核传递套接字地址结构的函数有3个:bind 、connect 和 sendto 。这些函数的一个参数是指向某个套接字地址结构的指针,另一个参数是该结构的整数大小,如:
connect(sockfd, (struct sockaddr *)&serv, sizeof(serv)); 既然指针和指针所指内容的大小都传递给了内核,于是内核知道到底需要从进程复制多少数据进来
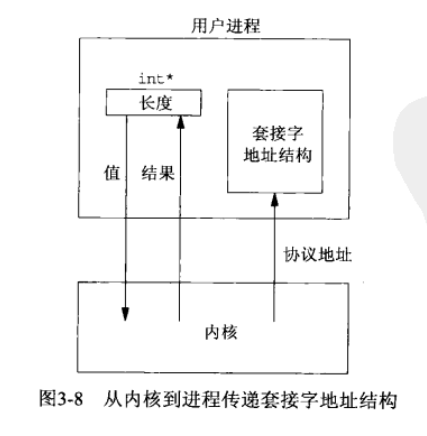
(2)从内核到进程传递套接字地址结构的函数有4个:accept 、recvfrom 、getsockname 和 getpeername 。这4个函数的其中两个参数是指向某个套接字地址结构的指针和指向表示该结构大小的整数变量的指针,如:
struct sockaddr_un cli; /* Unix domain */
socklen_t len;
len = sizeof(cli); /* len is a value */
getpeername(unixfd, (struct sockaddr *)&cli, &len);
/* len may have changed */把套接字地址结构大小这个参数从一个整数改为指向某个整数变量的指针,其原因在于:当函数被调用时,结构大小是一个值(value),它告诉内核该结构的大小,这样内核在写该结构时不至于越界;当函数返回时,结构大小又是一个结果(result),它告诉进程内核在该结构中究竟存储了多少信息。这种类型的参数称为值-结果参数
传递套接字地址结构的函数还有两个:recvmsg 和 sendmsg ,它们套接字地址结构的长度不是作为函数参数而是作为结构字段传递的
当使用值-结果参数作为套接字地址结构的长度时,如果套接字地址结构是固定长度的,那么从内核返回的值总是那个固定长度,例如 IPv4 的 sockaddr_in 长度是16,IPv6的 sockaddr_in6 长度是28。然而对于可变长度的套接字地址结构(如 Unix域的 sockaddr_un ),返回值可能小于该结构的最大长度
字节排序函数
考虑一个16位整数,它由2个字节组成。内存中存储这两个字节有两种方法:一种是将低序字节存储在起始地址,这称为小端字节序;另一种方法是将高序字节存储在起始地址,这称为大端字节序
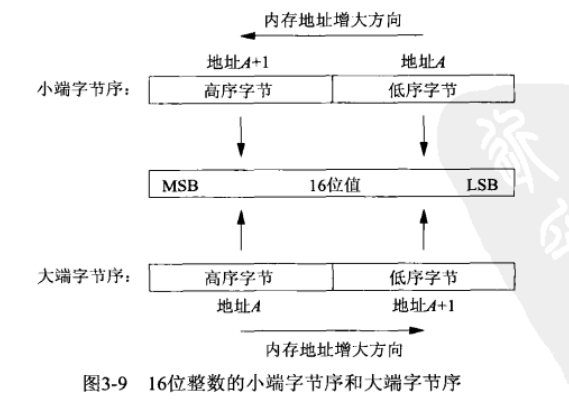
遗憾的是,这两种字节序之间没有标准可循,两种格式都有系统使用。我们把某个给定系统所用的字节序称为主机字节序,输出主机字节序程序如下:
#include <stdio.h>
int main() {
union {
short s;
char c[sizeof(short)];
} un;
un.s = 0x0102; // 小端: 0x01 <- 0x02
if (sizeof(short) == 2) {
if (un.c[0] == 1 && un.c[1] == 2)
printf("big-endian\n");
else if (un.c[0] == 2 && un.c[1] == 1)
printf("little-endian\n");
else
printf("unknown\n");
}
else
printf("sizeof(short) = %d\n", sizeof(short));
return 0;
} 既然网络协议必须制定一个网络字节序,作为网络编程人员的我们必须清楚不同字节序之间的差异。举例来说,在每个TCP分节中都有16位的端口号和32位的IPv4地址。发送协议栈和接收协议栈必须就这些多字节字段各个字节的传送顺序达成一致。网际协议使用大端字节序来传送这些多字节整数
从理论上说,具体实现可以按主机字节序存储套接字地址结构中的各个字段,等到需要在这些字段和协议首部相应字段之间移动时,再在主机字节序和网络字节序之间进行互转,让我们免于操心转换细节。然而由于历史的原因和 POSIX 规范的规定,套接字地址结构中的某些字段必须按照网络字节序进行维护。因此我们要关注如何在主机字节序和网络字节序之间相互转换。这两种字节序之间的转换使用以下 4 个函数:
#include <netinet/in.h>
uint16_t htons(uint16_t host16bitvalue);
uint32_t htonl(uint32_t host32bitvalue); // 均返回:网络字节序的值
uint16_t ntohs(uint16_t net16bitvalue);
uint32_t ntohl(uint32_t net32bitvalue); // 均返回:主机字节序的值 在这些函数的名字中,h 代表 host,n 代表 network,s 代表 short,l 代表 long。当使用这些函数时,我们并不关心主机字节序和网络字节序的真实值。我们所要做的只是调用适当的函数在主机和网络字节序之间转换某个给定值。在那些与网络协议所用字节序(大端)相同的系统中,这四个函数通常被定义为空宏
字节操纵函数
操纵多字节字段的函数有两组,它们既不对数据作解释,也不假设是以空字符结束的C字符串。当处理套接字地址结构时,我们需要对这些类型的函数,因为我们需要操纵诸如IP地址这样的字段,这些字段可能包含值为 0 的字节,却并不是 C 字符串。
名字以 b (表示字节)开头的第一组函数起源于4.2BSD,几乎所有现今支持套接字函数的系统仍然提供它们。名字以 mem (表示内存)开头的第二组函数起源于 ANSI C标准,支持 ANSI C 函数库的所有系统都提供它们
#include <strings.h>
void bzero(void *dest, size_t nbytes);
void bcopy(const void *src, void *dest, size_t nbytes);
int bcmp(const void *ptr1, const void *ptr2, size_t nbytes); // 相等返回0bzero 把目标字节串中指定数目的字节置为0。我们经常使用该函数来把一个套接字地址结构初始化为0。bcopy 将指定数目的字节从源字节串移到目标字节串。bcmp 比较两个任意的字节串,若相同则返回0,否则返回值非负
#include <string.h>
void *memset(void *dest, int c, size_t len);
void *memcpy(void *dest, const void *src, size_t nbytes);
int memcmp(const void *ptr1, const void *ptr2, size_t nbytes);memset 把目标字节串指定数目的字节置为c。memset 类似 bcopy ,不过两个指针参数的顺序是相反的。当源字节串与目标字节串重叠时,bcopy 能够正确处理,但是 memcpy 的操作结果却不可知。这种情形下必须改用 ANSI C 的 memmove 函数
memcpy 比较两个任意的字节串,若相同则返回 0,否则返回一个非 0 值,是大于 0 还是小于 0 取决于第一个不等的字节:如果 ptr1 所指的字节串中的这个字节大于 ptr2 所指字节中对应字节,那么大于 0,否则小于 0。我们的比较操作是在假设两个不等的字节均为无符号字符的前提下完成的
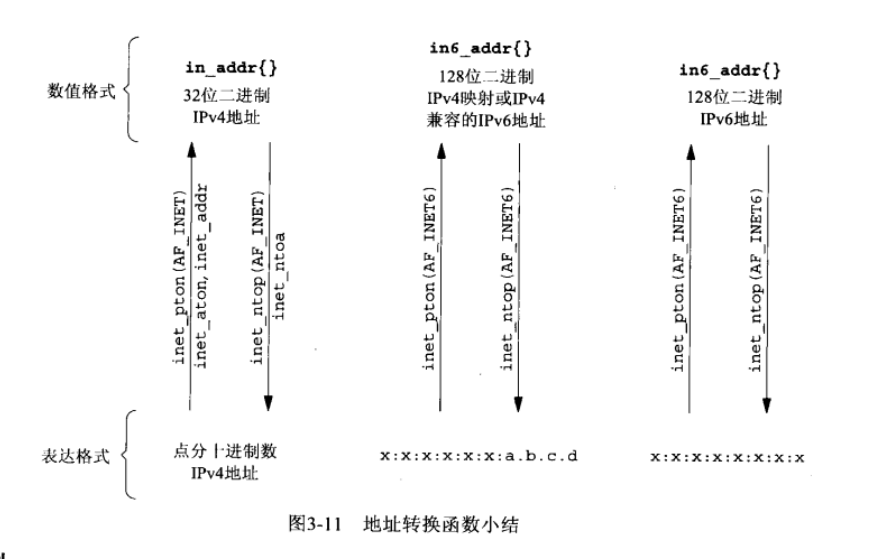
inet_aton、inet_addr 和 inet_ntoa 函数
(1)inet_aton 、inet_addr 和 inet_ntoa 在点分十进制数串(例如“206.168.112.96”)与它长度为 32 位的网络字节序二进制值间转换 IPv4 地址
(2)两个比较新的函数 inet_pton 和 inet_ntop 对于 IPv4 地址和 IPv6 地址都适用
#include <arpa/inet.h>
// 返回:若字符串有效则为1,否则为0
int inet_aton(const char *strptr, struct in_addr *addrptr);
// 返回:若字符串有效则为32位二进制网络字节序的IPv4地址,否则为INADDR_NONE(被废弃)
in_addr_t inet_addr(const char *strptr);
// 返回:指向一个点分十进制数串的指针
char *inet_ntoa(struct in_addr inaddr);如今 inet_addr 已被废弃,新的代码应该改用 inet_aton 函数。更好的办法是使用下一节中介绍的新函数,它们对于 IPv4 和 IPV6 都使用
inet_ntoa 函数将一个 32 位的网络字节序二进制 IPv4 地址转换成相应的点分十进制数串。由该函数的返回值所指向的字符串驻留在静态内存中。这意味着该函数是不可重入的(注意:该函数以一个结构而不是以指向该结构的一个指针作为其参数)
inet_pton 和 inet_ntop 函数
这两个函数是随 IPv6 出现的新函数,对于 IPv4 和 IPv6 地址都适用。函数名中 p 和 n分别代表 表达(presentation)和 数值(numeric)。地址的表达格式通常是 ASCII 字符串,数值格式则是存放到套接字地址结构中的二进制值
#include <arpa/inet.h>
// 返回:若成功则为 1,若输入不是有效的表达式格式则为 0,若出错则为 -1
int inet_pton(int family, const char *strptr, void *addrptr);
// 返回:若成功则为指向结果的指针,若出错则为NULL
const char *inet_ntop(int family, const void *addrptr, char *strptr, size_t len);这两个函数的 family 参数既可以是 AF_INET ,也可以是 AF_INET6 。如果以不被支持的地址族作为 family 参数,这两个函数就都返回一个错误,并将 errno 置为 EAFNOSUPPORT
第一个函数尝试转换由 strptr 指针所指的字符串,并通过 addrptr 指针存放二进制结果。若成功则返回值为1,否则如果对所指定的 family 而言输入的字符串不是有效的表达式格式,那么返回值为 0
inet_ntop 进行相反的转换,从数值格式(addrptr)转换到表达格式(strptr)。len 参数是目标存储单元的大小,以免该函数溢出其调用者的缓冲区。为有助于指定这个大小,在 <neinet/in.h> 头文件中有如下定义:
#define INET_ADDRSTRLEN 16 /* for IPv4 dotted-decimal */
#define INET6_ADDRSTRLEN 46 /* for IPv6 hex string */如果len太小,不足以容纳表达格式结果(包括结尾的空字符),那么返回一个空指针,并置 errno 为 ENOSPC
inet_ntop 函数的 strptr 参数不可以是一个空指针。调用者必须为目标存储单元分配内存并指定其大小。调用成功时,这个指针就是该函数的返回值
示例:
// 两种方式
foo.sin_addr.s_addr = inet_addr(cp);
inet_pton(AF_INET, cp, &foo.sin_addr); // 推荐
// 两种方式
ptr = inet_ntoa(foo.sin_addr);
// 推荐
char str[INET_ADDRSTRLEN];
ptr = inet_ntop(AF_INET, &foo.sin_addr, str, sizeof(str));
// 只支持 IPv4 的 inet_pton 函数的简单定义
int inet_pton(int family, const char *strptr, void *addrptr) {
if (family == AF_INET) {
struct in_addr in_val;
if (inet_aton(strptr, &in_val)) {
memcpy(addrptr, &in_val, sizeof(struct in_addr));
return 1;
}
return 0;
}
errno = EAFNOSUPPORT;
return -1;
}
// 只支持 IPv4 的 inet_ntop 函数的简单定义
const char *inet_ntop(int family, const void *addrptr, char *strptr, size_t len) {
const u_char *p = (const u_char *)addrptr;
if (family == AF_INET) {
char temp[INET_ADDRSTRLEN];
snprintf(temp, sizeof(temp), "%d.%d.%d.%d", p[0], p[1], p[2], p[3]);
if (strlen(temp) >= len) {
errno = ENOSPC;
return NULL;
}
strcpy(strptr, temp);
return strptr;
}
errno = EAFNOSUPPORT;
return NULL;
}sock_ntop 和相关函数
inet_ntop 的一个基本问题是:它要求调用者传递一个指向某个二进制地址的指针,而该地址通常包含在一个套接字地址结构中,这就要求调用者必须知道这个结构的格式和地址族。这就是说,为了使用这个函数,我们必须为 IPv4 编写如下代码:
struct sockaddr_in addr;
inet_ntop(AF_INET, &addr.sin_addr, str, sizeof(str));或为 IPv6 编写如下代码
struct sockaddr_in6 addr6;
inet_ntop(AF_INET6, &addr6.sin6_addr, str, sizeof(str));这就使得代码与协议相关了,为了解决这个问题,我们将自行编写一个名为 sock_ntop 的函数,它以指向某个套接字地址结构的指针为参数,查看该结构的内部,然后调用适当的函数返回该地址的表达式
// 返回:若成功则为非空指针,若出错则为 NULL
char *sock_ntop(const struct sockaddr *sockaddr, socklen_t addrlen) {
char portstr[8];
static char str[128]; /* Unix domain is largest */
switch (sa->sa_family) {
case AF_INET: {
struct sockaddr_in * sin = ( struct sockaddr_in *) sa;
if (inet_ntop(AF_INET, & sin ->sin_addr, str, sizeof (str)) == NULL)
return (NULL);
if (ntohs( sin ->sin_port) != 0) {
snprintf(portstr, sizeof (portstr), ":%d" , ntohs( sin ->sin_port));
strcat (str, portstr);
}
return (str);
}
/* end sock_ntop */
#ifdef IPV6
case AF_INET6: {
struct sockaddr_in6 *sin6 = ( struct sockaddr_in6 *) sa;
str[0] = '[' ;
if (inet_ntop(AF_INET6, &sin6->sin6_addr, str + 1, sizeof (str) - 1) == NULL)
return (NULL);
if (ntohs(sin6->sin6_port) != 0) {
snprintf(portstr, sizeof (portstr), "]:%d" , ntohs(sin6->sin6_port));
strcat (str, portstr);
return (str);
}
return (str + 1);
}
#endif
#ifdef AF_UNIX
case AF_UNIX: {
struct sockaddr_un *unp = ( struct sockaddr_un *) sa;
/* OK to have no pathname bound to the socket: happens on
every connect() unless client calls bind() first. */
if (unp->sun_path[0] == 0)
strcpy (str, "(no pathname bound)" );
else
snprintf(str, sizeof (str), "%s" , unp->sun_path);
return (str);
}
#endif
#ifdef HAVE_SOCKADDR_DL_STRUCT
case AF_LINK: {
struct sockaddr_dl *sdl = ( struct sockaddr_dl *) sa;
if (sdl->sdl_nlen > 0)
snprintf(str, sizeof (str), "%*s (index %d)" ,
sdl->sdl_nlen, &sdl->sdl_data[0], sdl->sdl_index);
else
snprintf(str, sizeof (str), "AF_LINK, index=%d" , sdl->sdl_index);
return (str);
}
#endif
default :
snprintf(str, sizeof (str), "sock_ntop: unknown AF_xxx: %d, len %d" ,
sa->sa_family, salen);
return (str);
}
return (NULL);
}readn、writen 和 readline 函数
字节流套接字(例如 TCP 套接字)上的 read 和 write 函数所表现的行为不同于通常的文件 I/O。字节流套接字上调用 read 或 write 输入或输出的字节数可能比请求的数量少,然而这不是出错的状态。这个现象的原因在于内核中用于套接字的缓冲区可能已到达了极限。此时所需的是调用者再次调用 read 和 write 函数,以输入或输出剩余的字节。为预防万一,不让实现返回一个不足的字节计数值,我们总是改为调用 writen 函数来取代 write 函数
// 以下3个函数是每当我们读或写一个字节流套接字时总要使用的函数
ssize_t readn(int filedes, void *buff, size_t nbytes);
ssize_t written(int filedes, const void *buff, size_t nbytes);
ssize_t readline(int filedes, void *buff, size_t maxlen);
// 均返回:读或写的字节数,若出错则为-1
/* 从一个描述符读n字节 */
ssize_t readn(int fd, void *vptr, size_t n) {
size_t nleft;
ssize_t nread;
char *ptr;
ptr = vptr;
nleft = n;
while (nleft > 0) {
if ( (nread = read(fd, ptr, nleft)) < 0) {
if (errno == EINTR)
nread = 0;
else
return -1;
}
else if (nread == 0)
break;
nleft -= nread;
ptr += nread;
}
return n - nleft;
}
/* 往一个描述符写n字节 */
ssize_t writen(int fd, const void *vptr, size_t n) {
size_t nleft;
ssize_t nwritten;
const char *ptr;
ptr = vptr;
nleft = n;
while (nleft > 0) {
if ( (nwritten = wirte(fd, ptr, nleft)) <= 0) {
if (nwritten < 0 && errno == EINTR)
nwritten = 0;
else
return -1;
}
nleft -= nwritten;
ptr += nwritten;
}
return n;
}
/* 从一个描述符读文本行,一次1个字节 */
ssize_t readline(int fd, void *vptr, size_t maxlen) {
ssize_t n, rc;
char c, *ptr;
ptr = vptr;
for (n = 1; n < maxlen; n++) {
again:
if ( (rc = read(fd, &c, 1)) == 1) {
*ptr++ = c;
if (c == '\n') /* newline is stored, like fgets() */
break;
}
else if (rc == 0) {
*ptr = 0;
return n - 1;
}
else {
if (errno == EINTR)
goto again;
return -1;
}
}
*ptr = 0;
return n;
}基本 TCP 套接字编程
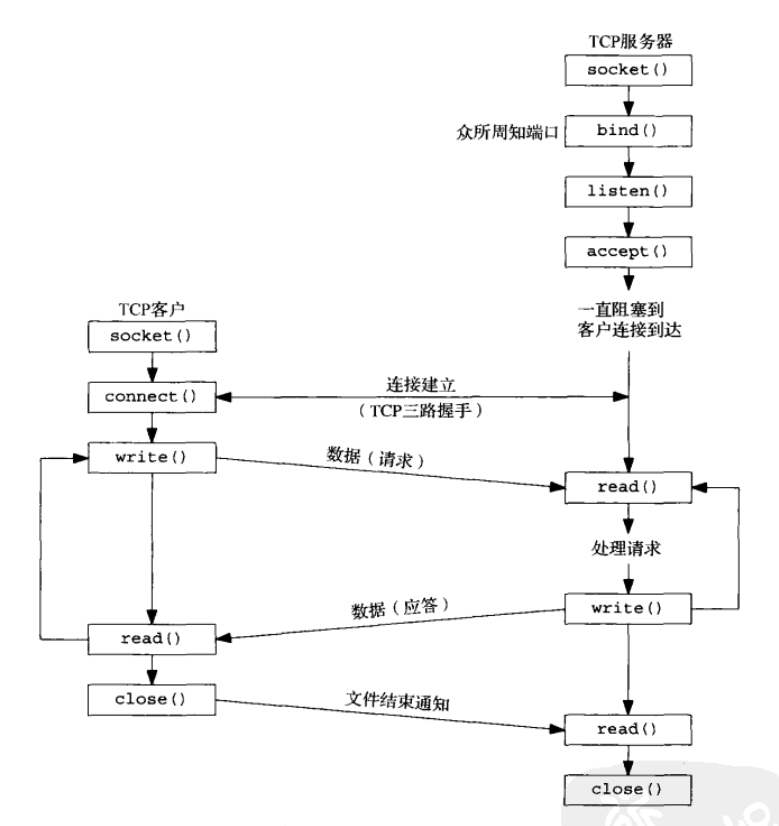
服务器首先启动,稍后某个时刻客户启动,它试图连接到服务器。我们假设客户给服务器发送一个请求,服务器处理该请求,并且给客户发回一个响应。这个过程一直持续下去,直到客户关闭连接的客户端,从而给服务器发送一个 EOF (文件结束)通知位置。服务器接着也关闭连接的服务器端,然后结束运行或者等待新的客户连接
socket 函数
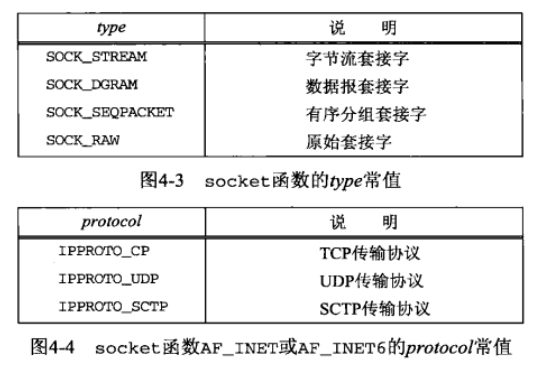
为了执行网络 I/O,一个进程必须做的第一件事情就是调用 socket 函数,指定期望的通信协议类型
#include <sys/socket.h>
// 返回:若成功则为非负描述符,若出错则为-1
int socket(int family, int type, int protocol);
// TCP是一个字节流协议,仅支持 SOCK_STREAM 套接字
// protocol 参数应设为某个协议类型常值,或者设为0,以选择所给点family和type组合的系统默认值

socket 函数在成功时返回一个小的非负整数值,它与文件描述符类似,我们把它称为套接字描述符(socket descriptor),简称 sockfd。为了得到套接字描述符,我们只是定义了协议族和套接字类型。我们并没有指定本地协议地址或远程协议地址
connect 函数
TCP客户用 connect 函数来建立与 TCP 服务器的连接
#include <sys/socket.h>
// 返回:若成功则为0,若出错则为-1
int connect(int sockfd, const struct sockaddr *servaddr, socklen_t addrlen); sockfd 是由 socket 函数返回的套接字描述符,第二个、第三个参数分别是一个指向套接字地址结构的指针和该结构的大小。套接字地址结构必须含有服务器的 IP 地址和端口号。
客户端在调用 connect 前不必非得调用 bind 函数,因为如果需要的话,内核会确定源 IP 地址,并选择一个临时端口作为源端口,如果是 TCP 套接字,调用 connect 函数将激发 TCP 的三路握手过程,而且仅在连接建立成功或出错时才返回。若 connect 失败则该套接字不再可用,必须关闭,我们不能对这样的套接字再次调用 connect 函数(当循环调用函数 connect 为给定主机尝试各个 IP 地址直到有一个成功时,在每次 connect 失败后,都必须 close 当前的套接字描述符并重新调用 socket )
bind 函数
bind 函数把一个本地协议地址赋予一个套接字。对于 IP 协议,协议地址是 32 位的 IPv4 地址或者 128 位的 IPv6 地址与 16 位的 TCP 或 UDP 端口号的组合
#include <sys/socket.h>
// 返回:若成功则为0,若出错则为-1
int bind(int sockfd, const struct sockaddr *myaddr, socklen_t addrlen);
// 从 bind 函数返回的一个常见错误是 EADDRINUSE(地址已使用)第二个参数是一个指定特定于协议的地址结构的指针,第三个参数是该地址协议结构的长度。对于 TCP,调用 bind 函数可以指定一个端口号,或指定一个 IP 地址,也可以两者都指定,还可以都不指定
服务器在启动时捆绑它们的众所周知端口。如果一个TCP客户或者服务器未曾调用 bind 捆绑一个端口,当调用 connect 或 listen 时,内核就要为相应的套接字选择一个临时端口。让内核来选择临时端口对于 TCP 客户来说是正常的,除非应用需要一个预留端口;然而对于 TCP 服务器来说却即为罕见,因为服务器是通过它们的众所周知端口被大家认识的
进程可以把一个特定的 IP 地址捆绑到它的套接字上,不过这个 IP 地址必须属于其所在主机的网络接口之一。对于 TCP 客户,这就为在该套接字上发送的 IP 数据报指派了源 IP 地址。对于 TCP 服务器,这就限定该套接字只接收哪些目的地为这个 IP 地址的客户连接。 TCP 客户通常不把 IP 地址捆绑到它的套接字上。当连接套接字时,内核将根据所用外出网络接口来选择源 IP 地址,而所用外出接口则取决于到达服务器所需的路径。如果 TCP 服务器没有把 IP 地址捆绑到它的套接字上,内核就把客户发送的 SYN 的目的 IP 地址作为服务器的源 IP 地址
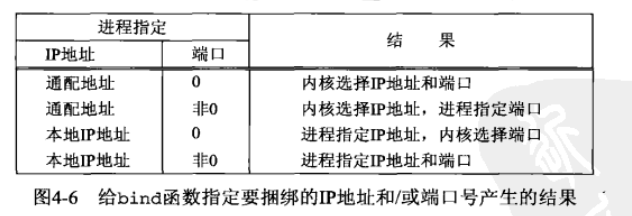
如果指定端口号位0,那么内核就在 bind 被调用时选择一个临时端口。然而如果指定 IP 地址为通配地址,那么内核将等到套接字已连接(TCP)或已在套接字上发出数据表(UDP)时,才选择一个本地 IP 地址
对于 IPv4来说,通配地址由常值 INADDR_ANY 来指定,其值一般为0。它告知内核去选择 IP 地址
对于 IPv6,我们就不能这么做了,因为 128 位的 IPv6地址是存放在一个结构中的,为了解决这个问题,我们改写为:
struct sockaddr_in6 serv;
serv.sin6_addr = in6addr_any;系统预先分配 in6arrd_any 变量并将其初始化为常值 IN6ADDR_ANY_INIT 。头文件 <neinet/in.h> 中含有 in6addr_any 的 extern 声明
无论是网络字节序还是主机字节序,INADDR_ANY 的值(为0)都一样,因此使用 htonl 并非必须。不过既然头文件 <netinet/in.h> 中定义的所有 INADDR_常值 都是按照主机字节序定义的,我们应该对任何这些常值都使用 htonl
为了得到内核所选择的这个临时端口值,必须调用函数 getsockname 来返回协议地址
listen 函数
listen 函数仅由 TCP 服务器调用,它做两件事情:
(1)当 socket 函数创建一个套接字时,它被假设为一个主动套接字,也就是说,它是一个将调用 connect 发起连接的客户套接字。listen 函数把一个未连接的套接字转换成一个被动套接字,指示内核应接受指向该套接字的连接请求。根据 TCP 状态转换图,调用 listen 导致套接字从 CLOSED 状态 转换到 LISTEN 状态
(2)本函数的第二个参数规定了内核应该为相应套接字排队的最大连接个数
#include <sys/socket.h>
// 返回:若成功则为0,出错为-1
int listen(int sockfd, int backlog);本函数通常应该在调用 socket 和 bind 这两个函数之后,并在调用 accept 函数之前调用
为了理解其中的 backlog 参数,我们必须认识到内核为任何一个给定的监听套接字维护两个队列:
(1)未完成连接队列:这些套接字处于 SYN_RCVD 状态
(2)已完成连接队列:这些套接字处于 ESTABLISHED 状态
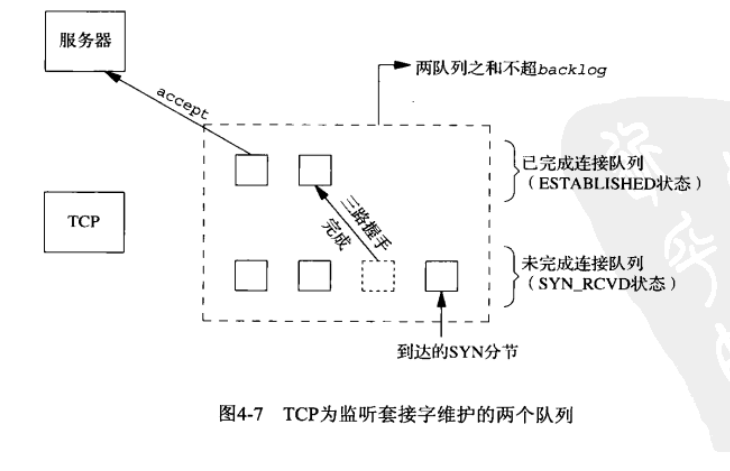
当进程调用 accept 时,已完成连接队列中的队头项将返回给进程,或者如果该队列为空,那么进程将被投入睡眠,直到 TCP 在该队列中放入一项才唤醒它。源自 Berkeley 的实现给 backlog 增设了一个模糊因子:把它乘以1.5得到未处理队列的最大长度,通常指定为 5 的 backlog 值实际上允许最多有 8 项在排队
不要把 backlog 定义为 0,因为不同的实现对此有不同的理解,如果你不想让任何客户连接到你的套接字上,那就关闭该套接字
那么这个 backlog 应该设为多少呢,我们通过修改 listen 函数的包裹函数就能够提供解决本问题的一个简单办法,运行环境变量 LISTENQ 覆写又调用者指定的值
void Listen(int fd, int backlog) {
char *ptr;
if ( (ptr = getenv("LISTENQ")) != NULL)
backlog = atoi(ptr);
if (listen(fd, backlog) < 0)
err_sys("listen error");
}accept 函数
accept 函数由 TCP 服务器调用,用于从已完成连接队列头返回下一个已完成连接。如果已完成连接队列为空,那么进程被投入睡眠(假定套接字为默认的阻塞方式)
#include <sys/socket.h>
// 返回:若成功则为非负描述符,若出错则为-1
int accept(int sockfd, struct sockaddr *cliaddr, socklen_t *addrlen);参数 cliaddr 和 addrlen 用来返回已连接的对端进程(客户)的协议地址。addrlen是值-结果参数:调用前,我们将由 *addrlen 所引用的整数值置为由 cliaddr 所指的套接字地址结构的长度,返回时,该整数值即为由内核存放在该套接字地址结构内的确切字节数
如果 accept 成功,那么其返回值是由内核自动生成的一个全新描述符,代表所返回客户的 TCP 连接。在讨论 accept 函数时,我们称它的第一个参数为监听套接字(listening socket)描述符(由 socket 创建,随后用作 bind 和 listen 的第一个参数的描述符),称它的返回值为已连接套接字(connected socket)描述符。一个服务器通常仅仅创建一个监听套接字,它在该服务器的生命期内一直存在。内核为每个服务器进程接受的客户连接一个已连接套接字。当服务器完成对某个给定客户的服务时,相应的套接字就被关闭
本函数最多返回三个值:一个既可能是新套接字描述符也可能是出错指示的整数、客户进程的协议地址以及该地址的大小。如果我们对返回客户协议地址不感兴趣,那么可以把 cliaddr 和 addrlen 均置为空指针
close 函数
close 函数用来关闭套接字,并终止 TCP 连接
#include <unistd.h>
// 返回:若成功则为0,若出错则为-1
int close(int sockfd);close 一个 TCP 套接字的默认行为是把该套接字标记成已关闭,然后立即返回到调用进程。该套接字描述符不能再由进程使用,也就是说它不能再作为 read 或 write 的第一个参数。然而 TCP 将尝试发送已排队等待发送到对端的任何数据,发送完毕后发生的是正常的 TCP 连接终止序列
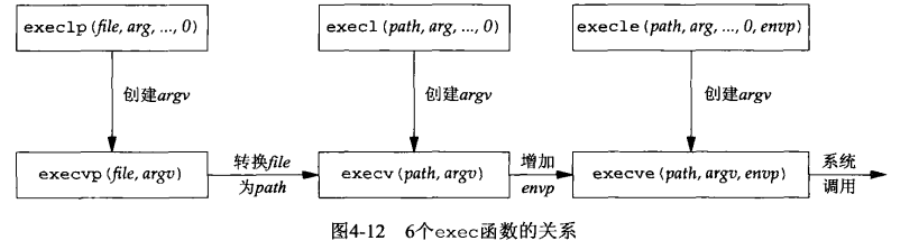
fork 和 exec 函数
#include <unistd.h>
// 返回:在子进程中为0,在父进程中为子进程ID,若出错则为-1
pid_t fork(void);理解 fork 最困难之处在于调用它一次,它却返回两次。它在调用进程(称为父进程)中返回一次,返回值是新派生进程(称为子线程)的进程ID号,在子进程又返回一次,返回值为0。因此,返回值本身告知当前进程是子进程还是父进程
fork在子进程返回 0 而不是父进程的进程 ID 的原因在于:任何子进程只有一个父进程,而且子进程总是可以通过调用 getppid 取得父进程的进程 ID。相反,父进程可以有许多子进程,而且无法获取各个子进程的进程 ID。如果父进程想要跟踪所有子进程的进程 ID,那么它必须记录每次调用 fork 的返回值
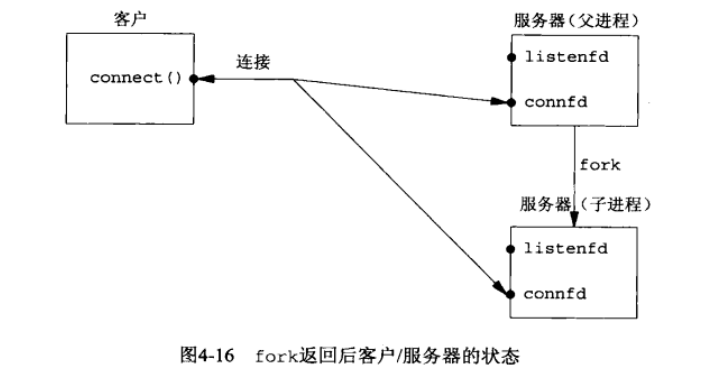
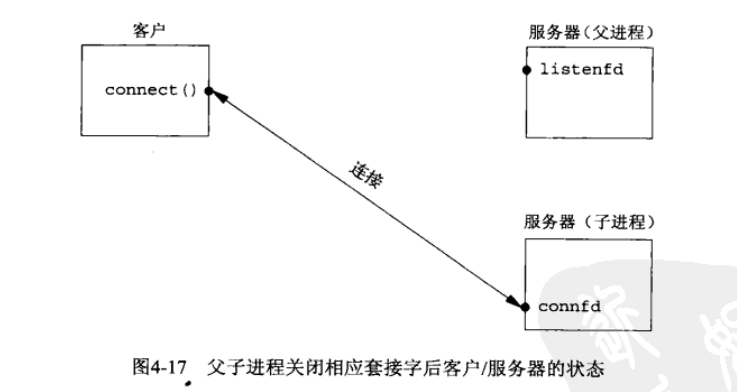
父进程中调用 fork 之前打开的所有描述符在 fork 返回之后由子进程分享。网络服务器利用了这个特性:父进程调用accept 之后调用 fork。所接受的已连接套接字随后就在父进程与子进程之间共享。通常情况下,子进程接着读写这个已连接套接字,父进程则关闭这个已连接套接字。
fork有两个典型用法:
(1)一个进程创建一个自身的副本,这样每个副本都可以在另一个副本执行其他任务的同时处理各自的某个操作。
(2)一个进程想要执行另一个程序。既然创建新进程的唯一办法是调用 fork,该进程于是首先调用 fork 创建一个自身的副本,然后其中一个副本(通常为子进程)调用 exec 把自身替换成新的程序。(exec 把当前进程映像替换成新的程序文件,而且该新程序通常从main函数开始执行。进程 ID 并不改变。我们称调用 exec 的进程为调用进程(calling process),称新执行的程序为新程序(new program))
#include <unistd.h>
int execl(const char *pathname, const char *arg0, ... /* (char*) 0 */);
int execv(const char *pathname, char *const *argv[]);
// envp用来存放环境变量的地址数组
int execle(const char *pathname, const char *arg0, ... /* (cahr *) 0, char *const envp[] */);
int execvpe(const char *pathname, char *const argv[], char *const envp[]);
int execlp(const char *filename, const char *arg0, ... /* (char *) 0 */);
int execvp(const char *filename, char *const argv[]);这些函数只在出错时才返回到调用者。否则,控制将被传递给新程序的起始点,通常就是 main 函数。
一般来说,只有 execve 是内核中的系统调用,其它 5 个都是调用 execve 的库函数
并发服务器
当服务一个客户请求可能花费较长时间时,我们并不希望整个服务器被单个客户长期占用,而是希望同时服务多个客户。Unix 中编写并发服务器程序的最简单办法就是 fork 一个子进程来服务每个客户。大多数 TCP 服务器是并发的,它们为每个待处理的客户连接调用 fork 派生一个子进程。
pid_t pid;
int listenfd, connfd;
listenfd = Socket(...);
Bind(listenfd, ...);
Linsten(listenfd, LISTENQ);
for ( ; ; ) {
connfd = Accept(listenfd, ...);
if ( (pid = Fork()) == 0) {
Close(listenfd); /* child closes listening socket */
doit(connfd); /* process the request */
Close(connfd); /* done with this client */
exit(0); /* child terminates */
}
Close(connfd); /* parent closes connected socket */
}
/*
解释:在父进程调用pid = Fork(),返回子进程的ID,子进程创建之后从main函数处重新执行,当子进程调用 pid = Fork()时返回0,这时进入循环,执行
doit(connfd)操作,执行完后退出即可;父进程由于将任务转交给了子进程,故可以关闭已连接套接字了
*/当一个连接建立时, accept 返回,服务器接着调用 fork,然后由子进程服务客户(通过已连接套接字 connfd),父进程则等待另一个连接(通过监听套接字listenfd)。既然新的客户由子进程提供服务,父进程就关闭已连接套接字。


僵尸进程
一个子进程在调用 return 或 exit(0) 结束自己的生命的时候,其实它并没有真正被销毁,而是留下一个僵死进程 。我们显然不愿意留存僵死进程。它们占用内核中的空间,最终可能导致我们耗尽进程资源。在 ps 命令输出的 CMD 栏以 <defunct> 指明僵死进程,无论何时我们 fork 子进程都得 wait 它们,以防它们变成僵死进程。为此我们建立一个俘获 SIGCHLD 信号的信号处理函数,这必须在 fork 第一个子进程之前完成,且只做一次。
值得关注的是,在某些系统下,如果一个进程把 SIGCHLD 的处置设定为 SIG_IGN ,它的子进程就不会变为僵死进程,即在主函数中添加:
#include <signal.h>
signal(SIGCHLD, SIG_IGN); // 忽略子进程退出的信号,避免产生僵死进程但是这种做法不具有可移植,处理僵死进程的可移植方法就是捕获 SIGCHLD,并调用 wait 或 waitpid
处理被中断的系统调用
我们用术语慢系统调用描述 accept 函数,该术语也适用于那些可能永远阻塞的系统调用。永远阻塞的系统调用是指调用有可能永远无法返回,多数网络支持函数都属于这一类。
适用于慢系统调用的基本规则是:当阻塞于某个慢系统调用的一个进程捕获某个信号且相应信号处理函数返回时,该系统调用可能返回一个 EINTR 错误。为了便于移植,我们必须对慢系统调用返回 EINTR 有所准备
for ( ; ; ) {
if ( (connfd = accept(sockfd, NULL, NULL) < 0) {
if (errno == EINTR)
continue;
else
perror("accept error");
}
}
// 不过有一个函数我们不能重启 : connect
// 如果该函数返回 EINTR,我们就不能再次调用它,否则将立即返回一个错误wait 和 waitpid 函数
处理已终止的子进程
#include <sys/wait.h>
// 均返回:若成功则为进程ID,若出错则为0或-1
pid_t wait(int *statloc);
pid_t waitpid(pid_t pid, int *statloc, int options);函数 wait 和 waitpid 均返回两个值:已终止子进程的进程ID号,以及通过 statloc 指针返回的子进程终止状态(一个整数)。我们可以调用三个宏来检查终止状态,并辨别子进程是正常终止、由某个信号杀死还是仅仅由作业控制停止。
如果调用 wait 的进程没有已终止的子进程,不过有一个或多个子进程仍在执行,那么 wait 将阻塞到现有子进程第一个终止为止
waitpid 函数就等待哪个进程以及是否阻塞给了我们更多的控制。首先,pid 参数允许我们制定想等待的进程 ID,值 -1 表示等待第一个终止的子进程。其次,options 参数允许我们指定附加选项。最常用的选项是 WNOHANG,它告知内核在没有已终止子进程时不要阻塞。
建立一个信号处理函数并在其中调用 wait 并不足以防止出现僵死进程。正确的解决办法是调用 waitpid 而不是 wait:我们在一个循环内调用 waitpid,以获取所有已终止子进程的状态,指定 WNOHANG 选项
// wait
void sig_chld(int signo) {
pid_t pid;
int stat;
pid = wait(&stat);
printf("child %d terminated\n", pid);
return;
}
// waitpid (正确)
void sig_chld(int signo) {
pid_t pid;
int stat;
while ( (pid = waitpid(-1, &stat, WNOHANG)) > 0)
printf("child %d terminated\n", pid);
return;
}并发服务器代码模板
void sig_chld(int);
int main(int argc, char **argv) {
int listenfd, connfd;
pid_t childpid;
socklen_t chilen;
struct sockaddr_in cliaddr, servaddr;
listenfd = Socket(AF_INET, SOCK_STREAM, 0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(SERV_PORT);
Bind(listenfd, (struct sockaddr *)&servaddr, sizeof(servaddr));
Listen(listenfd, LISTENQ);
Signal(SIGCHLD, sig_chld); /* must call waitpid */
for ( ; ; ) {
clilen = sizeof(cliaddr);
if ( (connfd = accept(listenfd, (struct sockaddr *)&cliaddr, &clilen)) < 0) {
if (errno == EINTR)
continue;
else{
prrer("accept error");
exit (EXIT_FAILURE);
}
}
if ( (childpid = Fork()) == 0) {
Close(listenfd);
doit(connfd); /* process the request */
exit(0);
}
Close(connfd);
}
}实例
1 #include <stdio.h>
2 #include <netinet/in.h>
3 #include <sys/socket.h>
4 #include <arpa/inet.h>
5 #include <unistd.h>
6 #include <stdlib.h>
7 #include <strings.h>
8 #include <signal.h>
9 #include <sys/wait.h>
10 #include <errno.h>
11
12 #define MAXLEN 512
13
14 void sig_chld(int signo) {
15 pid_t pid;
16 int stat;
17
18 while ( (pid = waitpid(-1, &stat, WNOHANG)) > 0)
19 printf("child %d terminated\n ", pid);
20
21 return;
22 }
23
24
25 void doit(int sockfd) {
26 ssize_t n;
27 char buf[MAXLEN];
28
29 while ( (n = recv(sockfd, buf, sizeof(buf), 0)) > 0) {
30 printf("读入了%ld个字节的数据\n", n);
31 buf[n] = '\0';
32 puts(buf);
33 }
34 pid_t parentpid = getppid();
35 pid_t selfpid = getpid();
36 printf("我是子进程pid = %d,我的任务完成了,父进程pid = %d\n", selfpid, parentpid);
37 }
38
39 int main(int argc, char **argv) {
40 // 一种解决僵死进程的办法,虽然方便,但是不推荐
41 // signal(SIGCHLD, SIG_IGN);
42
43 pid_t childpid;
44 int sockfd, connfd;
45 sockfd = socket(AF_INET, SOCK_STREAM, 0);
46 if (sockfd == -1) {
47 perror("sockfd error");
48 exit (EXIT_FAILURE);
49 }
50
51 struct sockaddr_in serv;
52 bzero(&serv, sizeof(serv));
53
54 serv.sin_family = AF_INET;
55 serv.sin_port = htons(7777);
56
57 inet_pton(AF_INET, "172.19.47.4", &serv.sin_addr);
58 bind(sockfd, (struct sockaddr *)&serv, sizeof(serv));
59 listen(sockfd, 16);
60 // 解决僵死进程
61 signal(SIGCHLD, sig_chld);
62 for( ; ; ) {
63 if ( (connfd = accept(sockfd, NULL, NULL)) < 0) {
64 if (errno == EINTR)
65 continue;
66 else {
67 perror("accept error");
68 exit (EXIT_FAILURE);
69 }
70 }
71
72 if ( (childpid = fork()) == 0) {
73 close(sockfd);
74 doit(connfd);
75 close(connfd);
76 exit(0);
77 }
78 printf("创建了一个子进程, id = %d\n", childpid);
79 close(connfd);
80 }
81 close(sockfd);
82
83 return 0;
84 }getsockname 和 getpeername 函数
这两个函数或者返回某个套接字关联的本地协议地址(getsockname),或者返回与某个套接字关联的外地协议地址(getpeername)
#include <sys/socket.h>
int getsockname(int sockfd, struct sockaddr *localaddr, socklen_t *addrlen);
int getpeername(int sockfd, struct sockaddr *peeraddr, socklen_t *addrlen);注意,这两个函数的最后一个参数都是值-结果参数。这就是说,这两个函数都得装填由 localaddr 或 peeraddr 指针所指的套接字地址结构
需要这两个函数的理由如下所述:
- 在一个没有调用 bind 的 TCP 客户上, connect 成功返回后,getsockname 用于返回由内核赋予该连接的本地 IP 地址和端口号
- 在以端口号0调用 bind(告知内核去选择本地端口号)后,getsockname 用于返回由内核赋予的本地端口号
- getsockname 可以用于获取某个套接字的地址族
- 在一个以通配 IP 地址调用 bind 的 TCP 服务器上,与某个客户的连接一旦建立(accept成功返回),getsockname就可以用于返回由内核赋予该连接的本地 IP 地址。
- 当一个服务器是由调用过 accept 的某个进程通过调用 exec 执行程序时,它能够获取客户身份的唯一途径便是调用 getpeername
例子:获取套接字的地址族
int sockfd_to_family(int sockfd) {
struct sockaddr_storage ss;
socklen_t len;
len = sizeof(ss);
if (getsockname(sockfd, (struct sockaddr *)&ss, &len) < 0)
return -1;
return ss.ss_family;
}recv 和 send函数
这两个函数类似标准的 read 和 write 函数,不过需要一个额外的参数
#include <sys/socket.h>
// 返回:若成功则为读入或写出的字节数,若出错则为-1
// 注意这两个函数只能用于socket通信
ssize_t recv(int sockfd, void *buff, size_t nbytes, int flags);
ssize_t send(int sockfd, const void *buff, size_t nbytes, int flags);recv 和 send的前三个参数等同于 read 和 write 的3个参数。flags 参数的值或为0,或为如下列出的一个或多个常值的逻辑或
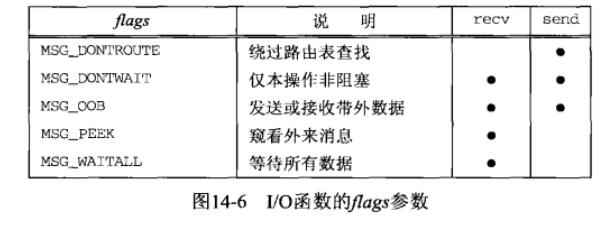
flags参数在设计上存在一个基本问题:它是按值传递的,而不是一个值-结果参数。因此它只能用于从进程向内核传递标志。内核无法向进程传回标志。
gethostbyname 和 gethostbyaddr 函数
gethostbyname函数根据主机名获取主机的完整信息,gethostbyaddr函数根据IP地址获取主机的完整信息。gethostbyname函数通常先在本地的 /etc/hosts 配置文件中查找主机,如果没有找到,再去访问 DNS 服务器
#include <netdb.h>
struct hostent* gethostbyname(const char* name);
struct hostent* gethostbyaddr(const void* addr, size_t len, int type);name参数指定目标主机的主机名,addr 参数指定目标主机的 IP 地址,len 参数指定 addr 所指的 IP 地址,type 参数指定 addr 所指 IP 地址的类型,其合法取值包括 AF_INET 和 AF_INET6
// hostent 结构体的定义如下
#include <netdb.h>
struct hostent {
char* h_name; /* 主机名 */
char** h_aliases; /* 主机别名列表, 可能有多个 */
int h_addrtype; /* 地址类型(地址族)*/
int h_length; /* 地址长度 */
char** h_addr_list; /* 按网络字节序列出的主机 IP 地址列表 */
};getservbyname 和 getservbyport
getservbyname 函数根据名称获取某个服务的完整信息, getservbyport 函数根据端口号获取某个服务的完整信息。它们实际上都是通过读取 /etc/services 文件来获取服务的信息的。
#include <netdb.h>
struct servent* getservbyname(const char* name, const char* proto);
struct servent* getservbyport(int port, const char* proto);name 参数指定目标服务的名字,port 参数指定目标服务对应的端口号。proto 参数指定服务类型,给它传递 “tcp” 表示获取流服务,给它传递 “udp” 表示获取数据报服务,给它传递 NULL 则表示获取所有类型的服务
// 结构体 servent 的定义如下:
#include <netdb.h>
struct servent {
char* s_name; /* 服务名称 */
char** s_aliases; /* 服务的别名列表, 可能有多个 */
int s_port; /* 端口号 */
char* s_proto; /* 服务类型,通常的tcp 或者 udp */
};需要指出的是,上面讨论的4个函数都是不可重入的,即非线程安全的。不过 netdb.h 头文件给出了它们的可重入版本。正如 Linux 下所有其他函数的可重入版本的命名规则那样,这些函数的函数名是在原函数名尾部加上 _r (re_entrant)
高级 I/O 函数
pipe 函数
pipe 函数可用于创建一个管道,以实现进程间通信
#include <unistd.h>
int pipe(int fd[2]); pipe 函数的参数是一个包含两个 int 型整数的数组指针。该函数成功时返回 0,并将一对打开的文件描述符值填入其参数指向的数组。如果失败则返回 -1 并设置 errno
通过 pipe 函数创建的这两个文件描述符 fd[0] 和 fd[1] 分别构成管道的两端,往 fd[1] 写入的数据可以从 fd[0] 读出。并且,fd[0] 只能用于从管道中读出数据,fd[1] 则只能用于往管道写入数据,而不能反过来使用。如果要实现双向的数据传输,就应该使用两个管道。默认情况下,这一对文件描述符都是阻塞的。
管道内部传输的数据是字节流,本身拥有一个容量限制,自 Linux 2.6.11 内核起,管道容量的大小默认是 65536 字节。我们可以使用 fcntl 函数来修改管道容量。
socketpair 函数
能够方便地创建双向管道
#include <sys/types.h>
#include <sys/socket.h>
int socketpair(int domain, int type, int protocol, int fd[2]); socketpair 前三个参数的含义与 socket 系统调用的三个参数完全相同,但 domain 只能使用 UNIX 本地域协议族 AF_UNIX ,因为我们仅能在本地使用这个双向管道。最后一个参数和 pipe 系统调用的参数一样,只不过创建的这对文件描述符都是既可读又可写的。成功时返回0,失败时返回-1并设置errno
dup 函数和 dup2 函数
有时我们希望把标准输出重定向到一个文件,或者把标准输出重定向到一个网络连接(比如 CGI 编程)。可以通过以下两个函数来实现:
#include <unistd.h>
int dup(int file_descriptor);
int dup2(int file_descriptor_one, int file_descriptor_two);dup 函数创建一个新的文件描述符,该新文件描述符和原有文件描述符 file_descriptor 指向相同的文件、管道或者网络连接。并且 dup 返回的文件描述符总是取系统当前可用的最小整数值。dup2 和 dup 类似,不过它将返回第一个不小于 file_descriptor_two 的整数值。失败时返回-1并设置errno
注意:通过 dup 和 dup2 创建的文件描述符并不继承原文件描述符的属性
// CGI 服务器原理 : 将标准输出重定向到网络连接
// 关闭标准输出文件描述符
close(STDOUT_FILENO);
// 复制socket文件描述符
dup(connfd);
// 因为dup的特点,返回值为之前关闭的标准输出文件描述符的值(1)
// 这样一来,服务器输出到标准输出的内容就会直接发送到与客户连接对应的socket上readv 函数和 writev 函数
readv 函数将数据从文件描述符读到分散的内存块中,即 分散读 ;writev 函数则将多块分散的内存数据一并写入文件描述符中,即 集中写 。
#include <sys/uio.h>
ssize_t readv(int fd, const struct iovec* vector, int count);
ssize_t writev(int fd, const struct iovec* vector, int count);fd 参数是被操作的目标文件描述符。vector 参数的类型是 iovec 结构体数组。该结构描述一块内存区。count 参数的内存块数。成功时返回读出/写入 fd 的字节数,失败则返回-1并设置errno
// iovec 结构体的定义
struct iovec {
void *iov_base; /* 内存起始地址 */
size_t iov_len; /* 这块内存的长度 */
};当 Web 服务器解析完一个 HTTP 请求之后,如果目标文档存在且客户具有读取该文档的权限,那么它就需要发送一个 HTTP 应答来传输该文档。这个 HTTP 应答包含 1 个状态行、多个头部字段、1 个空行和文档内容。其中,前三部分的内容可能被 Web 服务器放置在一块内存中,而文档的内容则通常被读入到另一块单独的内存中。我们并不需要把这两部分内容拼接到一起再发送,而是可以使用 writev 函数将它们同时写出
// Web 服务器上的集中写
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <stdbool.h>
#include <sys/uio.h>
#define BUFFER_SIZE 1024
static const char* status_line[2] = { "200 OK", "500 Internal server error"};
int main(int argc, char* argv[]) {
if (argc <= 3) {
printf("Please input three argument\n");
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
const char* file_name = argv[3];
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int sock = socket(PF_INET, SOCK_STREAM, 0);
assert(sock >= 0);
int ret = bind(sock, (struct sockaddr *)&address, sizeof(address));
ret = listen(sock, 5);
assert(ret != -1);
int connfd = accept(sock, NULL, NULL);
if (connfd < 0) {
printf("errno is: %d\n", errno);
}
else {
char header_buf[BUFFER_SIZE];
memset(header_buf, '\0', BUFFER_SIZE);
char* file_buf = NULL;
struct stat file_stat;
bool valid = true;
int len = 0;
if (stat(file_name, &file_stat) < 0) {
valid = false;
}
else {
if (S_ISDIR(file_stat.st_mode)) {
valid = false;
}
else if(file_stat.st_mode & S_IROTH) {
int fd = open(file_name, O_RDONLY);
file_buf = (char*)calloc(file_stat.st_size + 1, sizeof(char));
if (read(fd, file_buf, file_stat.st_size) < 0) {
valid = false;
}
}
else valid = false;
}
if (valid) {
ret = snprintf(header_buf, BUFFER_SIZE - 1, "%s %s\r\n", "HTTP/1.1", status_line[0]);
len += ret;
ret = snprintf(header_buf + len, BUFFER_SIZE - 1 - len,
"Content-Length: %ld\r\n", file_stat.st_size);
len += ret;
ret = snprintf(header_buf + len, BUFFER_SIZE - 1 - len,
"%s", "\r\n");
struct iovec iv[2];
iv[0].iov_base = header_buf;
iv[0].iov_len = strlen(header_buf);
iv[1].iov_base = file_buf;
iv[1].iov_len = file_stat.st_size;
ret = writev(connfd, iv, 2);
}
else {
ret = snprintf(header_buf, BUFFER_SIZE - 1, "%s %s\r\n", "HTTP/1.1", status_line[1]);
len += ret;
ret = snprintf(header_buf + len, BUFFER_SIZE - 1 - len, "%s", "\r\n");
send(connfd, header_buf, strlen(header_buf), 0);
}
close(connfd);
if (!file_buf) {
free(file_buf);
}
}
close(sock);
return 0;
}sendfile 函数
sendfile 函数在两个文件描述符之间直接传递数据(完全在内核中操作),从而避免了内核缓冲区和用户缓冲区之间的数据拷贝,效率很高,这被称为零拷贝。
#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t* offset, size_t count);in_fd 参数是待读出内容的文件描述符,out_fd 参数的待写入内容的文件描述符,offset 参数指定从读入文件流的哪个位置开始读,如果为空,则使用读入文件流默认的起始位置。count 参数指定在文件描述符之间传递的字节数。成功时返回传递的字节数,失败则返回 -1 并设置errno
in_fd 必须是一个支持类似 mmap 函数的文件描述符,即它必须指向真实的文件,不能是 socket 和管道;而 out_fd 则必须是一个 socket(也可以是标准输出)。
// 利用 sendfile 函数将服务器上的一个文件传动给客户端
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/sendfile.h>
int main(int argc, char* argv[]) {
if (argc <= 3) return 1;
const char* ip = argv[1];
int port = atoi(argv[2]);
const char* file_name = argv[3];
int filefd = open(file_name, O_RDONLY);
assert(filefd > 0);
struct stat stat_buf;
fstat(filefd, &stat_buf);
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int sock = socket(PF_INET, SOCK_STREAM, 0);
assert(sock >= 0);
int ret = bind(sock, (struct sockaddr*)&address, sizeof(address));
assert(ret != -1);
ret = listen(sock, 5);
assert(sock != -1);
int connfd = accept(sock, NULL, NULL);
if (connfd < 0) {
printf("errno is: %d\n", errno);
}
else {
sendfile(connfd, filefd, NULL, stat_buf.st_size);
close(connfd);
}
close(sock);
return 0;
}相比上一个例子,使用 sendfile 没有目标文件分配任何用户空间的缓存,也没有执行读取文件的操作(只打开了文件),但同样实现了文件的发送,效率要高得多。
mmap 函数和 munmap 函数
mmap 函数用于申请一段内存空间。我们可以将这段内存空间作为进程间通信的共享内存,也可以将文件之间映射到其中。 munmap 函数则释放由 mmap 创建的这段内存空间
#include <sys/mman.h>
void* mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *start, size_t length);start 参数允许用户使用某个特定的地址作为这段内存的起始地址。如果它别设置成 NULL,则系统自动分配一个地址。length 参数指定内存段的大小。prot 参数用来设置内存段的访问权限:
- PROT_READ,内存段可读
- PROT_WRITE,内存段可写
- PROT_EXEC,内存段可执行
- PROT_NONE,内存段不能被访问
flags 参数控制内存段内容被修改后程序的行为。fd 参数是被映射文件对应的文件描述符。它一般通过 open 系统调用获得。 offset 参数设置从文件的何处开始映射(对于不需要读入整个文件的情况)
成功时返回指向目标内存区域的指针,失败则返回 MAP_FAILED((void*)-1)并设置 errno。munmap 函数成功时返回0,失败时返回-1并设置 errno
splice 函数
splice 函数用于在两个文件描述符之间移动数据,也是零拷贝操作
#define _GNU_SOURCE
#include <fcntl.h>
ssize_t splice(int fd_in, loff* off_in, int fd_out, loff_t* off_out,
size_t len, unsigned int flags);fd_in 参数是待输入数据的文件描述符。如果 fd_in 是一个管道文件描述符,那么 off_in 参数必须被设置为 NULL。如果 fd_in 不是一个管道文件描述符,那么 off_in 表示从输入数据流的何处开始读取数据。此时,若 off_in 被设置为 NULL,则表示从输入数据流的当前偏移位置读入。fd_out/off_out 参数的含义与 fd_in/off_in 相同,不过用于输出数据流。len 参数指定移动数据的长度。flags 参数则控制数据如何移动:
- SPLICE_F_MOVE : 如果合适的话,按整页内存移动数据,这只是给内核的一个提示。不过,因为它的实现存在 BUG,所以自内核 2.6.21 后,它实际上没有任何效果
- SPLICE_F_NOBLOCK : 非阻塞的 splice 操作,但实际效果还会受文件描述符本身的阻塞状态的影响
- SPLICE_F_MORE : 给内核的一个提示,后序的 splice 调用将读取更多数据
- SPLICE_F_GIFT : 对 splice 没有效果
使用 splice 函数时, fd_in 和 fd_out 必须至少有一个是管道文件描述符。splice 函数调用成功时返回移动字节数的数量。失败时返回-1并设置 errno
// 使用 splice 函数实现一个零拷贝的回射服务器:它将客户端发送的数据原样返回给客户端
#define _GNU_SOURCE
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/sendfile.h>
#include <sys/stat.h>
int main(int argc, char* argv[]) {
if (argc <= 2) {
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int sock = socket(PF_INET, SOCK_STREAM, 0);
int ret = bind(sock, (struct sockaddr*)&address, sizeof(address));
ret = listen(sock, 5);
int connfd = accept(sock, NULL, NULL);
if (connfd < 0) {
printf("errno is: %d\n", errno);
}
else {
int pipefd[2];
ret = pipe(pipefd);
ret = splice(connfd, NULL, pipefd[1], NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE);
assert(ret != -1);
ret = splice(pipefd[0], NULL, connfd, NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE);
assert(ret != -1);
close(connfd);
}
close(sock);
return 0;
}tee 函数
tee 函数在两个管道文件描述符之间复制数据,也是零拷贝操作。它不消耗数据,因此源文件描述符上的数据仍然可以用于后续的读操作
#include <fcntl.h>
ssize_t tee(int fd_in, int fd_out, size_t len, unsigned int flags);该函数的参数的含义与 splice 相同(但 fd_in 和 fd_out 必须都是管道文件描述符)。tee 函数成功时返回在两个文件描述符之间复制的数据量(字节数)。返回0表示没有复制任何数据。失败时返回-1并设置 errno
// 同时输出数据到终端和文件的程序
#define _GNU_SOURCE
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
int main(int argc, char* argv[]) {
if (argc != 2) {
return 1;
}
int filefd = open(argv[1], O_CREAT | O_WRONLY | O_TRUNC, 0666);
assert(filefd > 0);
int pipefd_stdout[2];
int ret = pipe(pipefd_stdout);
assert(ret != -1);
int pipefd_file[2];
ret = pipe(pipefd_file);
assert(ret != -1);
ret = splice(STDIN_FILENO, NULL, pipefd_stdout[1], NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE);
assert(ret != -1);
// 将管道 pipefd_stdout 的输出复制到管道 pipefd_file 的输入端
ret = tee(pipefd_stdout[0], pipefd_file[1], 32768, SPLICE_F_NONBLOCK);
assert(ret != -1);
ret = splice(pipefd_file[0], NULL, filefd, NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE);
assert(ret != -1);
ret = splice(pipefd_stdout[0], NULL, STDOUT_FILENO, NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE);
assert(ret != -1);
close(filefd);
close(pipefd_stdout[0]);
close(pipefd_stdout[1]);
close(pipefd_file[0]);
close(pipefd_file[1]);
return 0;
}fcntl 函数
fcntl 函数(file control)。提供了对文件描述符的各种控制操作。
#include <fcntl.h>
int fcntl(int fd, int cmd, ...);fd 参数是被操作的文件描述符,cmd 参数指定执行何种类型的操作。根据操作类型的不同,该函数可能还需要第三个可选参数 arg 。在网络编程中,fcntl 函数通常用来将一个文件描述符设置为非阻塞的。
int setnonblocking(int fd) {
int old_option = fcntl(fd, F_GETFL); /* 获取文件描述符旧的状态标志 */
int new_option = old_option | O_NONBLOCK; /* 设置为非阻塞标志 */
fcntl(fd, F_SETFL, new_option);
return old_option; /* 返回文件描述符旧的状态标志,以便日后恢复该状态标志 */
}I/O复用
I/O复用使得程序能同时监听多个文件描述符,这对提高程序的性能至关重要。使用场景:
- 客户端程序需要同时处理多个 socket
- 客户端程序要同时处理用户输入和网络连接
- TCP 服务器要同时处理监听 socket 和连接 socket
- 服务器要同时处理 TCP 请求和 UDP 请求
- 服务器要同时监听多个端口,或者处理多种服务
I/O 复用虽然能同时监听多个文件描述符,但它本身是阻塞的。如果要实现并发,只能使用多进程或多线程等编程手段。
select 系统调用
select 系统调用的用途是:在一段指定时间内,监听用户感兴趣的文件描述符上的可读、可写和异常等事件。
#include <sys/select.h>
int select(int nfds, fd_set* readfds, fd_set* writefds, fd_set* exceptfds, struct timeval* timeout);
// fd_set 结构体定义如下
typedef struct {
__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS];
} fd_set;
// fd_set 结构体仅包含一个整型数组,该数据的每个元素的每一位标记一个文件描述符
// 能容纳的文件描述符数量由 FD_SETSIZE 指定,这就限制了 select 能同时处理的文件描述符的数量
/* 由于位操作过于繁琐, 我们应该使用下面的一系列宏来访问 fd_set 结构体中的位 */
FD_ZERO(fd_set* fdset); /* 清除 fdset 的所有位 */
FD_SET(int fd, fd_set* fdset); /* 设置 fdset 的位fd */
FD_CLR(int fd, fd_set* fdset); /* 清除 fdset 的位fd */
int FD_ISSET(int fd, fd_set* fdset);/* 测试 fdset 的位 fd s是否被设置 */nfds 参数指定被监听的文件描述符的总数,通常被设置为 select 监听的所有文件描述符中的最大值加1,因为文件描述符是从0开始计数的
readfds 、writefds 和 exceptfds 参数分别指向可读、可写和异常等事件对应的文件描述符集合,select 调用返回时,内核将修改它们来通知应用程序哪些文件描述符已经就绪
timeout 参数用来设置 select 函数的超时时间,它是一个 timeval 结构类型的指针,采用指针参数是因为内核将修改它以告诉应用程序 select 等待了多久。不过我们不能完全信任 select 调用返回后的 timeout 值,比如调用失败时 timeout 值是不确定的,timeval 结构体的定义如下:
struct timeval {
long tv_sec; /* 秒数 */
long tv_usec; /* 微妙数 */
};如果给 timeout 传递 NULL,则 select 将一直阻塞,直到某个文件描述符就绪
select 成功时返回就绪(可读、可写和异常)文件描述符的总数。如果在超时时间内没有任何文件描述符就绪,select 将返回0。select 失败时返回-1并设置 errno。如果在 select 等待期间,程序接收到信号,则 select 立即返回-1,并设置 errno 为 EINTR
// 同时接收普通数据和带外数据
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/select.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
int main(int argc, char* argv[]) {
if (argc <= 2) {
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
int connfd = accept(listenfd, NULL, NULL);
if (connfd < 0) {
printf("errno is: %d\n", errno);
close(listenfd);
close(listenfd);
return 1;
}
char buf[1024];
fd_set read_fds;
fd_set exception_fds;
FD_ZERO(&read_fds);
FD_ZERO(&exception_fds);
while (1) {
memset(buf, '\0', sizeof(buf));
FD_SET(connfd, &read_fds);
FD_SET(connfd, &exception_fds);
ret = select(connfd + 1, &read_fds, NULL, &exception_fds, NULL);
if (ret < 0) {
puts("selection failure");
break;
}
if (FD_ISSET(connfd, &read_fds)) {
ret = recv(connfd, buf, sizeof(buf) - 1, 0);
if (ret <= 0) {
break;
}
printf("get %d bytes of normal data: %s\n", ret, buf);
}
else if (FD_ISSET(connfd, &exception_fds)) {
ret = recv(connfd, buf, sizeof(buf) - 1, MSG_OOB);
if (ret <= 0) {
break;
}
printf("get %d bytes of oob data: %s\n", ret, buf);
}
}
close(connfd);
close(listenfd);
return 0;
}poll 系统调用
poll 系统调用和 select 类似,也是在指定时间内轮询一定数量的文件描述符,以测试其中是否有就绪者
#include <poll.h>
int poll(struct pollfd* fds, nfds_t nfds, int timeout);fds 参数是一个 pollfd 结构类型的数组,它定义所有我们感兴趣的文件描述符上发生的可读、可写和异常等事件。pollfd 结构体的定义如下:
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 注册的事件 */
short revents; /* 实际发生的事件, 由内核填充 */
};其中, fd 成员指定文件描述符;events 成员告诉 poll 监听 fd 上的哪些事件,它是一系列事件的按位或;revents 成员则由内核修改,以通知应用程序 fd 上实际发生了哪些事件,poll 事件类型如下:
- POLLIN : 数据可读(包括普通数据和优先数据)
- POLLRDNORM:普通数据可读
- POLLRDBAND:优先级带数据可读(Linux不支持)
- POLLRPI:高优先级数据可读,比如 TCP 带外数据
- POLLOUT:数据可写(包括普通数据和优先数据)
- POLLWRNORM:普通数据可写
- POLLWRBAND:优先级带数据可写
- POLLRDHUP:TCP 连接被对方关闭,或者对方关闭了写操作(它由GNU引入)
- POLLERR :错误
- POLLHUP:挂起
- POLLNVAL:文件描述符没有打开
自 Linux 内核 2.6.17 开始, GNU 为 poll 系统调用增加了一个 POLLRDHUP 事件,它在 socket 上接收到对方关闭连接的请求之后出发。但使用时我们需要在代码最开始处定义 _GNU_SOURCE
nfds 参数指定被监听事件集合 fds 的大小,其类型 nfds_t 的定义如下:
typedef unsigned long int nfds_t;timeout 参数指定 poll 的超时值,单位是毫秒。当 timeout 为 -1 时,poll 调用将永远阻塞,直到某个事件发生;当 timeout 为0时,poll 调用将立即返回
epoll 系列系统调用
内核事件表
epoll 是 Linux 持有的 I/O 复用函数。它在实现和使用上与 select 、poll 有很大差异。epoll 使用一组函数来完成任务,而不是单个函数。把用户关系的文件描述符上的事件放在内核的一个事件表中,从而无需像 select 和 poll 那样每次调用都要重复传入文件描述符集或事件集。但 epoll 需要使用一个额外的文件描述符,来唯一标识内核中的这个事件表
#include <sys/epoll.h>
int epoll_create(int size)size 参数现在并不起作用,只是给内核一个提醒,告诉它事件表需要多大。该函数返回的文件描述符将作用于其他所有 epoll 系统调用的第一个参数,以指定要访问的内核事件表
// 操作内核事件表
#include <sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);fd 参数是要操作的文件描述符, op 参数指定操作类型,有如下几种:
- EPOLL_CTL_ADD:往事件表中注册
fd上的事件 - EPOLL_CTL_MOD :修改
fd上的注册事件 - EPOLL_CTL_DEL:删除
fd上的注册事件
event 参数指定事件,它是 epoll_event 结构指针类型,其定义如下:
struct epoll_event {
__uint32_t events; /* epoll 事件 */
epoll_data_t data; /* 用户数据 */
};其中 event 成员描述事件类型。epoll 支持的类型和 poll 基本相同。表示 epoll 事件类型的宏是在 poll 对应的宏前加上 “E”,但 epoll 有两个额外的时间类型——EPOLLET 和 EPOLLONESHOT。
data 成员用于存储用户数据,其类型 epoll_data_t 定义如下:
typedef union epoll_data {
void* ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;epoll_data_t 是一个联合体,其中四个成员中用的最多是 fd ,它指定事件所属的目标文件描述符。
epoll_ctl 成功时返回0,失败则返回-1并设置 errno
epoll_wait 函数
epoll 系列系统调用的主要接口是 epoll_wait 函数。它在一段超时时间内等待一组文件描述符上的事件:
#include <sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout);maxevents 参数指定最多监听多少个事件,它必须大于0
epfd 即 epoll_create 返回的描述符
events 是一个结构体数组,用于输出 epoll_wait 检测到的就绪事件,而不像 select 和 poll 的数组那样既用于传入用户注册的事件,又用于输出内核检测到的就绪事件。极大地提高了应用程序索引就绪文件描述符的效率
LT 和 ET 模式
epoll 对文件描述符的操作有两种模式:LT(Level Trigger,电平触发)模式和 ET(Edge Trigger,边沿触发)模式。LT 模式是默认的工作模式,而当往 epoll 内核事件表中注册一个文件描述符上的 EPOLLET 事件时,epoll 将以 ET 模式来操作该文件描述符。ET 模式是 epoll 的高效工作模式
对于采用 LT 工作模式的文件描述符,当 epoll_wait 检测到其上有事件发生并将此事件通知应用程序后,应用程序可以不立即处理该事件。
对于采用 ET 工作模式的文件描述符,应用程序必须立即处理该事件,因为后序的 epoll_wait 调用将不再向应用程序通知这一事件。ET 模式在很大程度上降低了同一个 epoll 事件被重复触发的次数,因此效率要比 LT 模式高
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <pthread.h>
#include <sys/epoll.h>
#include <stdbool.h>
#define MAX_EVENT_NUMBER 1024
#define BUFFER_SIZE 10
typedef struct epoll_event epoll_event;
/* 将文件描述符设置成非阻塞的 */
int setnonblocking(int fd) {
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
/* 将文件描述符 fd 上的 EPOLLIN 注册到 epollfd 指示的 epoll 内核事件表中, 根据参数 enable_et 指定是否对 fd 启用 ET 模式 */
void addfd(int epollfd, int fd, bool enable_et) {
epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN;
if (enable_et) {
event.events |= EPOLLET;
}
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}
/* LT 模式的工作流程 */
void lt(epoll_event* events, int number, int epollfd, int listenfd) {
char buf[BUFFER_SIZE];
for (int i = 0; i < number; i++) {
int sockfd = events[i].data.fd;
if (sockfd == listenfd) {
int connfd = accept(listenfd, NULL, NULL);
addfd(epollfd, connfd, false);
}
else if (events[i].events & EPOLLIN) {
/* 只要socket读缓冲中还有未读出的数据,这段代码就被触发 */
printf("event trigger once\n");
memset(buf, '\0', BUFFER_SIZE);
int ret = recv(sockfd, buf, BUFFER_SIZE - 1, 0);
if (ret <= 0) {
close(sockfd);
continue;
}
printf("get %d bytes of content: %s\n", ret, buf);
}
else {
printf("something else happened\n");
}
}
}
/* ET 模式的工作流程 */
void et(epoll_event* events, int number, int epollfd, int listenfd) {
char buf[BUFFER_SIZE];
for (int i = 0; i < number; i++) {
int sockfd = events[i].data.fd;
if (sockfd == listenfd) {
int connfd = accept(listenfd, NULL, NULL);
addfd(epollfd, connfd, true);
}
else if (events[i].events & EPOLLIN) {
/* 这段代码不会被重复触发,所以我们循环读取数据,以确保把 socket 读
* 缓存中的所有数据读出*/
printf("event trigger onece\n");
while (1) {
memset(buf, '\0', BUFFER_SIZE);
int ret = recv(sockfd, buf, BUFFER_SIZE - 1, 0);
if (ret < 0) {
if ( (errno == EAGAIN) || (errno == EWOULDBLOCK)) {
printf("read later\n");
break;
}
close(sockfd);
break;
}
else if (ret == 0) {
close(sockfd);
}
else {
printf("get %d bytes of content: %s\n", ret, buf);
}
}
}
else {
printf("something else happened\n");
}
}
}
int main(int argc, char* argv[]) {
if (argc <= 3) {
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
const char* mode = argv[3];
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
epoll_event events[MAX_EVENT_NUMBER];
int epollfd = epoll_create(5);
assert(epollfd != -1);
addfd(epollfd, listenfd, true);
while (1) {
int ret = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if (ret < 0) {
printf("epoll failure\n");
break;
}
if (strcasecmp(mode, "ET") == 0) {
et(events, ret, epollfd, listenfd);
}
else {
lt(events, ret, epollfd, listenfd);
}
}
close(listenfd);
return 0;
}注意:每个使用 ET 模式的文件描述符都应该是非阻塞的。如果文件描述符是阻塞的,那么读或写操作将会因为没有后续的事件而一直处于阻塞状态(饥渴状态)
EPOLLONESHOT 事件
即使我们使用 ET 模式,一个 socket 上的某个事件还是可能被触发多次。这在并发程序中就会引起一个问题。比如一个线程(或进程)在读取完某个 socket 上的数据后开始处理这些数据,而在数据的处理过程中该 socket 上又有新数据可读(EPOLLIN 再次被触发),此时另外一个线程被唤醒来读取这些新的数据。于是就出现了两个线程同时操作一个线程处理。这一点可以使用 epoll 的 EPOLLONESHOT 事件实现
对于注册了 EPOLLONESHOT 事件的文件描述符,操作系统最多触发其上注册的一个可读、可写或者异常事件,且只触发一次,除非我们使用 epoll_ctl 函数重置该文件描述符上注册的 EPOLLONESHOT 事件。这样,当一个线程在处理某个 socket 时,其他线程是不可能有机会操作该 socket 的。注册了 EPOLLONESHOT 事件的 socket 一旦被某个线程处理完毕,该线程就应该立即重置这个 socket 上的 EPOLLONESHOT 事件,以确保这个 socket 下一次可读时,其 EPOLLIN 事件能被触发,进而让其他工作线程有机会继续处理这个 socket
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <pthread.h>
#define MAX_EVENT_NUMBER 1024
#define BUFFER_SIZE 1024
struct fds {
int epollfd;
int sockfd;
};
int setnonblocking(int fd) {
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
void addfd(int epollfd, int fd, bool oneshot) {
epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN | EPOLLET;
if (oneshot) {
event.events |= EPOLLONESHOT;
}
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}
void reset_oneshot(int epollfd, int fd) {
epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN | EPOLLET | EPOLLONESHOT;
epoll_ctl(epollfd, EPOLL_CTL_MOD, fd, &event);
}
void* worker(void* arg) {
int sockfd = ( (fds*)arg)->sockfd;
int epollfd = ( (fds*)arg)->epollfd;
printf("start new thread to recevie data on fd: %d\n", sockfd);
char buf[BUFFER_SIZE];
memset(buf, '\0', BUFFER_SIZE);
while (1) {
int ret = recv(sockfd, buf, BUFFER_SIZE - 1, 0);
if (ret == 0) {
close(sockfd);
printf("foreiner closed the connection\n");
break;
}
else if (ret < 0) {
if (errno == EAGAIN) {
reset_oneshot(epollfd, sockfd);
printf("read later\n");
break;
}
}
else {
printf("get content: %s\n", buf);
/* 休眠5s, 模拟数据处理过程 */
sleep(5);
}
}
printf("end thread receiving data on fd: %d\n", sockfd);
pthread_exit(0);
}
int main(int argc, char* argv[]) {
if (argc <= 2) {
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
epoll_event events[MAX_EVENT_NUMBER];
int epollfd = epoll_create(5);
assert(epollfd != -1);
addfd(epollfd, listenfd, false);
while (1) {
int ret = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if (ret < 0) {
printf("epoll failure\n");
break;
}
for (int i = 0; i < ret; i++) {
int sockfd = events[i].data.fd;
if (sockfd == listenfd) {
int connfd = accept(listenfd, NULL, NULL);
addfd(epollfd, connfd, true);
}
else if (events[i].events & EPOLLIN) {
pthread_t thread;
fds fds_for_new_worker;
fds_for_new_worker.epollfd = epollfd;
fds_for_new_worker.sockfd = sockfd;
pthread_create(&thread, NULL, worker, (void*)&fds_for_new_worker);
}
else {
printf("something else happened\n");
}
}
}
close(listenfd);
return 0;
}信号
信号是由用户、系统或者进程发送给目标进程的信息,以通知目标进程某个状态的改变或系统异常
- 对于前台进程,用户可以通过输入特殊的终端字符来给它发送信号。比如输入 Ctrl + C通常会给进程发送一个终端信号(SIGINT),也可以通过 kill 命令发送指定信号到指定进程
kill -SIGxxx pid - 系统异常。比如浮点异常和非法内存段访问
- 系统状态变化。比如
alarm定时器到期将引起 SIGALRM 信号 - 运行 kill 命令或调用 kill 函数
服务器程序必须处理(或至少忽略)一些常见的信号,以免异常终止
发送信号
Linux 下,一个进程给其他进程发送信号的 API 是 kill 函数
#include <sys/types.h>
#include <signal.h>
// 该函数把信号发送给目标进程: 目标进程由 pid 参数指定
// 成功时返回0,失败时返回 -1并设置 errno
int kill(pid_t pid, int sig);
/*
pid > 0 : 信号发送给 PID 为 pid 的进程
pid = 0 : 信号发送给本进程组内的其他进程
pid = -1: 信号发送给除 init 进程外的所有进程,但发送这需要拥有对目标进程发送信号的权限
pid < -1: 信号发送给组 ID 为 -pid 的进程组中的所有成员
*/
/*
sig = 0 : kill 函数不发送任何信号(但可以用来检测目标进程或进程组是否存在, 但是不靠谱)
*/
/* errno 的可能值
EINVAL : 无效的信号
EPERM : 该进程没有权限发送信号给任何一个目标进程
ESRCH : 目标进程或进程组不存在
*/信号处理方式
目标进程在收到信号时,需要定义一个接收函数来处理
#include <signal.h>
typedef void (*__sighandler_t) (int);
// 信号处理函数应该是可重入的,否则很容易引发一些竞态条件
// 所以在信号处理函数中严禁调用一些不安全的函数除了用户自定义信号处理函数为,还有信号的其它两种处理方式
#include <bits/signum.h>
#define SIG_DFL ((__sighandler_t) 0)
#define SIG_IGN ((__sighandler_t) 1)SIG_IGN 表示忽略目标信号,SIG_DFL 表示使用信号的默认处理方式
中断系统调用
如果程序在执行处于阻塞状态的系统调用时接收到信号,并且我们为该信号设置了信号处理函数,则默认情况下系统调用将被中断,并且 errno 将被设置为 EINTR。我们可以使用 sigaction 函数为信号设置 SA_RESTART 标志以自动重启被该信号中断的系统调用
signal 系统调用
为一个信号设置处理函数
#include <signal.h>
_sighandler_t signal(int sig, _sighandler_t _handler);sig 参数指出要捕获的信号类型。_handler 参数是 _sighandler_t 类型的函数指定,用于指定信号 sig 的处理函数,调用出错时返回 SIG_ERR,并设置 errno
sigaction 系统调用
设置信号处理函数更健壮的接口是如下的系统调用:
#include <signal.h>
int sigaction(int sig, const struct sigaction* act, struct sigaction* oact);sig 参数指出要捕获的信号类型,act 参数指定新的信号处理方式,oact 参数则输出信号先前的处理方式(如果不为 NULL 的话)。act 和 oact 都是 sigaction 结构体类型的指针,其定义如下:
struct sigaction {
#ifdef __USE_POSIX199309
union {
_sighandler_t sa_handler;
void (*sa_sigaction) (int, siginfo_t*, void*);
}
_sigaction_handler;
#define sa_handler __sigaction_handler.sa_handler
#define sa_sigaction __sigaction_handler.sa_sigaction
#elseif
_sigset_t sa_mask;
int sa_flags;
void (*sa_restorer) (void);
};sa_hander 成员指定信号处理函数
sa_mask 成员设置进程的信号掩码,以指定哪些信号不能发送给本进程
sa_flags 成员用于设置程序收到信号时的行为,常用的有 :
- SA_NOCLDWAIT : 如果 sigaction 的
sig参数是SIGCHLD,则设置该标志表示子进程结束时不产生僵尸进程 - SA_RESTART :重新调用被该信号终止的系统调用
信号集函数
Linux 使用数据结构 sigset_t 来表示一组信号:
#include <bits/sigset.h>
#define _SIGSET_NWORDS (1024 / (8 * sizeof (unsigned long int)))
typedef struct {
unsigned long int __val[_SIGSET_NWORDS];
} __sigset_t;sigset_t 实际上是一个长整型数组,数组的每个元素的每个位表示一个信号。Linux 提供了如下一组函数来设置、修改、删除和查询信号集:
#include <signal.h>
int sigemptyset(sigset_t* _set); /* 清空信号集 */
int sigfillset(sigset_t* _set); /* 在信号集中设置所有信号(常用来设置sa_mask) */
int sigaddset(sigset_t* _set, int _signo); /* 将信号 _signo 添加至信号集中 */
int sigdelset(sigset_t* _set, int _signo); /* 将信号 _signo 从信号集中删除 */
int sigismember(_const sigset_t* _set, int _signo); /* 测试 _signo 是否在信号集中 */进程信号掩码
我们可以利用 sigaction 结构体的 sa_mask 成员来设置进程的信号掩码,此外如下函数也可以用于设置或查看进程的信号掩码:
#include <signal.h>
int sigprocmask(int _how, _const sigset_t* _set, sigset_t* _oset);_set 参数指定新的信号掩码,_oset 参数则输出原来的信号掩码(如果不为NULL的话)
如果_set 参数不为NULL,则 _how 参数指定设置进程信号掩码的方式:
- SIG_BLOCK : 新的进程信号掩码是其当前值和
_set指定信号集的并集 - SIG_UNBLOCK : 新的进程信号掩码是其当前值和
~_set信号集的交集,因此_set指定的信号集将不被屏蔽 - SIG_SETMASK : 直接将进程信号掩码设置为
_set
如果 _set 为 NULL,则进程信号掩码不变,此时依然可以用 _oset 来获得进程当前的信号掩码
sigprocmask 成功时返回0,失败则返回 -1 并设置 errno
被挂起的信号
设置进程信号掩码后,被屏蔽的信号将不能被进程接收。如果给进程发送一个被屏蔽的信号,则操作系统将该信号设置为进程的一个被挂起的好,如果我们取消对被挂起信号的屏蔽,则它能立即被进程接收到
// 好的进程当前被挂起的信号集
int sigpending(sigset_t* set);set 参数用于保存被挂起的信号集。成功时返回0,失败时返回-1并设置 errno
统一事件源
信号是一种异步事件:信号处理函数和主程序的主循环是两条不同的执行路线。统一事件源即统一处理信号和 I/O 事件。信号处理函数通常使用管道来讲信号“传递”给主循环,然后主循环再根据接收到的信号值执行目标信号对应的逻辑代码
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <stdbool.h>
#define MAX_EVENT_NUMBER 1024
typedef struct epoll_event epoll_event;
static int pipefd[2];
int setnonblocking(int fd) {
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
void addfd(int epollfd, int fd) {
epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN | EPOLLET;
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}
/* 信号处理函数 */
void sig_handler(int sig) {
int save_errno = errno;
int msg = sig;
send(pipefd[1], (char*)&msg, 1, 0); /* 每个信号值占一个字节 */
errno = save_errno;
}
/* 设置信号的处理函数 */
void addsig(int sig) {
struct sigaction sa;
memset(&sa, '\0', sizeof(sa));
sa.sa_handler = sig_handler;
sa.sa_flags |= SA_RESTART;
sigfillset(&sa.sa_mask);
assert(sigaction(sig, &sa, NULL) != -1);
}
int main(int argc, char** argv) {
if (argc <= 2) {
return 1;
}
pid_t pid = getpid();
printf("本进程的PID为: %d\n", pid);
const char* ip = argv[1];
int port = atoi(argv[2]);
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
ret = listen(listenfd, 5);
epoll_event events[MAX_EVENT_NUMBER];
int epollfd = epoll_create(5);
assert(epollfd != -1);
addfd(epollfd, listenfd);
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, pipefd);
assert(ret != -1);
setnonblocking(pipefd[1]);
addfd(epollfd, pipefd[0]);
/* 设置一些信号的处理函数 */
addsig(SIGHUP);
addsig(SIGCHLD);
addsig(SIGTERM);
addsig(SIGINT);
bool stop_server = false;
while (!stop_server) {
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if ( (number < 0) && (errno != EINTR)) {
printf("epoll failure\n");
break;
}
if (number > 0) printf("就绪的文件描述符有%d个\n", number);
for (int i = 0; i < number; i++) {
int sockfd = events[i].data.fd;
if (sockfd == listenfd) {
int connfd = accept(listenfd, NULL, NULL);
addfd(epollfd, connfd); /* 添加客户连接,不过这里没有对客户连接进行处理 */
}
else if ( (sockfd == pipefd[0]) && (events[i].events & EPOLLIN)) {
/* 当信号触发时,通过管道传输信号信息,做相应处理 */
puts("信号触发");
int sig;
char signals[1024];
ret = recv(pipefd[0], signals, sizeof(signals), 0);
if (ret == -1) {
continue;
}
else if (ret == 0) {
continue;
}
else {
for (int j = 0; j < ret; ++j) {
switch(signals[j])
{
case SIGCHLD:
case SIGHUP:
{
puts("我被挂起了");
continue;
}
case SIGTERM:
case SIGINT:
{
puts("我被中断了");
stop_server = true;
}
}
}
}
}
else {
}
}
}
printf("close fds\n");
close(listenfd);
close(pipefd[1]);
close(pipefd[0]);
return 0;
}网络编程相关信号
- SIGHUP : 当挂起进程的控制终端时,SIGHUP 信号将被触发
- SIGPIPE : 默认情况下,往一个读端关闭的管道或 socket 连接中写数据将引发 SIGPIPE 信号。程序接收到 SIGPIPE 信号的默认行为是结束进程,而我们绝对不希望因为错误的写操作而导致程序退出。引起 SIGPIPE 信号的写操作将设置 errno 为 EPIPE,我们可以使用 send 函数的 MSG_NOSIGNAL 标志来禁止写操作触发 SIGPIPE 信号,这种情况下,我们应该使用 send 函数反馈的 errno 值来判断管道或者 socket 连接的读端是否已经关闭
- SIGURG : 程序带外数据到达
// 用 SIGURG 检测带外数据是否到达
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <signal.h>
#include <fcntl.h>
#define BUF_SIZE 1024
static int connfd;
void sig_urg(int sig) {
int save_errno = errno;
char buffer[BUF_SIZE];
memset(buffer, '\0', BUF_SIZE);
int ret = recv(connfd, buffer, BUF_SIZE - 1, MSG_OOB);
printf("get %d bytes of oob data '%s'\n", ret, buffer);
errno = save_errno;
}
void addsig(int sig, void (*sig_handler)(int)) {
struct sigaction sa;
memset(&sa, '\0', sizeof(sa));
sa.sa_handler = sig_handler;
sa.sa_flags |= SA_RESTART;
sigfillset(&sa.sa_mask);
assert(sigaction(sig, &sa, NULL) != -1);
}
int main(int argc, char** argv) {
if (argc <= 2) {
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int sock = socket(PF_INET, SOCK_STREAM, 0);
int ret = bind(sock, (struct sockaddr*)&address, sizeof(address));
ret = listen(sock, 5);
connfd = accept(sock, NULL, NULL);
if (connfd < 0) {
printf("errno is: %d\n", errno);
}
else {
addsig(SIGURG, sig_urg);
fcntl(connfd, F_SETOWN, getpid());
char buffer[BUF_SIZE];
while (1) {
memset(buffer, '\0', BUF_SIZE);
ret = recv(connfd, buffer, BUF_SIZE - 1, 0); // 接收普通数据
if (ret <= 0) {
break;
}
printf("get %d bytes of normal data '%s'\n", ret, buffer);
}
close(connfd);
}
close(sock);
return 0;
}定时器
网络程序需要处理的第三类事件是定时事件,比如定期检测一个客户连接的活动状态。服务器程序通常管理这众多定时事件,因此有效地组织这些定时事件,使之能在预期的时间点被触发且不影响服务器的主要逻辑,对于服务器的性能有着至关重要的影响。为此,我们要将每个定时器事件分别封装成定时器,并使用某种容器类数据结构将所有的定时器串联起来,以实现对定时事件的统一管理
定时是指在一段时间之后触发某段代码的机制,我们可以在这段代码中依次处理所有到期的定时器。Linux 提供了三种定时方法:
- socket 选项 SO_RCVTIMEO 和 SO_SNDTIMEO
- SIGALRM 信号
- I/O 复用系统调用超时函数
socket 选项 SO_RCVTIMEO 和 SO_SNDTIMEO
它们分别用来设置 socket 接收数据超时时间和发送数据超时时间。因此,这两个选项仅对于数据接收和发送相关的 socket 专用系统调用有效
- send、sendmsg、connect : SO_SNDTIMEO
超时行为:返回-1并设置errno,send、sendmsg(EAGAIN 或 EWOULDBLOCK),connect(EINPROGRESS)
- recv、recvmsg、accept : SO_RCVTIMEO
超时行为:返回-1并设置errno,recv、recvmsg、accept(EAGAIN 或 EWOULDBLOCK)
// 设置 connect 超时时间
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <stdlib.h>
#include <assert.h>
#include <stdio.h>
#include <errno.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int timeout_connect(const char* ip, int port, int time) {
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int sockfd = socket(PF_INET, SOCK_STREAM, 0);
struct timeval timeout;
timeout.tv_sec = time;
timeout.tv_usec = 0;
socklen_t len = sizeof(timeout);
ret = setsockopt(sockfd, SOL_SOCKET, SO_SNDTIMEO, &timeout, len);
ret = connect(sockfd, (struct sockaddr*)&address, sizeof(address));
if (ret == -1) {
if (errno == EINPROGRESS) {
printf("connecting timeout, process timeout logic\n");
return -1;
}
printf("error occur when connecting to server\n");
return -1;
}
return sockfd;
}
int main(int argc, char** argv) {
if (argc <= 2) {
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
int sockfd = timeout_connect(ip, port, 10);
if (sockfd < 0) {
return 1;
}
close(sockfd);
return 0;
} SIGALRM 信号
由 alarm 和 setitimer 函数设置的实时闹钟一旦超时,将触发 SIGALRM 信号。因此,我们可以利用该信号的信号处理函数来处理定时任务。但是,如果要处理多个定时任务,我们就需要不断地触发 SIGALRM 信号,并在其信号处理函数中执行到期的任务。一般而言, SIGALRM 信号按照固定的频率生成,即由 alarm 或 setitimer 函数设置的定时周期 T 保持不变。
基于升序链表的定时器
定时器通常至少要包含两个成员:一个超时时间(相对时间或绝对时间)和一个任务回调函数。有的时候还可能包含回调函数被执行时需要传入的参数, 以及是否重启定时器等信息。
// lst_timer.h
#ifndef LST_TIMER
#define LST_TIMER
#include <time.h>
#define BUFFER_SIZE 64
class util_timer;
struct client_data {
sockaddr_in address;
int sockfd;
char buf[BUFFER_SIZE];
util_timer* timer;
};
class util_timer {
public:
util_timer() : prev(nullptr), next(nullptr) {};
public:
time_t expire;
void (*cb_func)(client_data*);
client_data* user_data;
util_timer* prev;
util_timer* next;
};
class sort_timer_lst {
public:
sort_timer_lst() : head(new util_timer), tail(new util_timer)
{
head->next = tail;
tail->prev = head;
}
~sort_timer_lst()
{
util_timer* tmp = head;
while (tmp) {
head = tmp->next;
delete tmp;
tmp = head;
}
}
void add_timer(util_timer* timer) {
if (!timer) {
return;
}
util_timer* tmp = head->next;
while (tmp->next) {
if (timer->expire < tmp->expire) {
timer->next = tmp;
timer->prev = tmp->prev;
tmp->prev->next = timer;
tmp->prev = timer;
return;
}
tmp = tmp->next;
}
/* 应该插在最尾部 */
timer->next = tail;
timer->prev = tail->prev;
tail->prev->next = timer;
tail->prev = timer;
}
void del_timer(util_timer* timer) {
if (!timer) {
return;
}
timer->next->prev = timer->prev;
timer->prev->next = timer->next;
timer->next = timer->prev = nullptr;
delete timer;
}
/* 检查升序链表中是否有超时任务 */
void tick() {
printf("timer tick\n");
time_t cur = time(NULL); /* 获得系统当前时间 */
util_timer* tmp = head->next;
while (tmp != tail) {
if (cur < tmp->expire) {
break;
}
tmp->cb_func(tmp->user_data);
util_timer* del = tmp;
tmp = tmp->next;
del_timer(del);
}
}
private:
util_timer* head;
util_timer* tail;
};
#endif判断定时任务到期的依据是定时器的 expire 值小于当前的系统时间
处理非活动连接
在应用层实现类似于 KEEPALIVE 的机制,以管理所有长时间处于非活动状态的连接
// 关闭非活动连接
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include "lst_timer.h"
#define FD_LIMIT 65535
#define MAX_EVENT_NUMBER 1024
#define TIMESLOT 5
static int pipefd[2];
static sort_timer_lst timer_lst;
static int epollfd = 0;
int setnonblocking(int fd) {
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
void addfd(int epollfd, int fd) {
epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN | EPOLLET;
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}
void sig_handler(int sig) {
int save_errno = errno;
int msg = sig;
send(pipefd[1], (char*)&msg, 1, 0);
errno = save_errno;
}
void addsig(int sig) {
struct sigaction sa;
memset(&sa, '\0', sizeof(sa));
sa.sa_handler = sig_handler;
sa.sa_flags |= SA_RESTART;
sigfillset(&sa.sa_mask);
assert(sigaction(sig, &sa, NULL) != -1);
}
void timer_handler() {
timer_lst.tick();
alarm(TIMESLOT);
}
void cb_func(client_data* user_data) {
epoll_ctl(epollfd, EPOLL_CTL_DEL, user_data->sockfd, 0);
assert(user_data);
close(user_data->sockfd);
printf("close fd %d\n", user_data->sockfd);
}
int main(int argc, char** argv) {
if (argc <= 2) {
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
assert(listenfd >= 0);
ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
epoll_event events[MAX_EVENT_NUMBER];
epollfd = epoll_create(5);
assert(epollfd != -1);
printf("epollfd = %d\n", epollfd);
addfd(epollfd, listenfd);
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, pipefd);
assert(ret != -1);
setnonblocking(pipefd[1]);
addfd(epollfd, pipefd[0]);
addsig(SIGALRM);
addsig(SIGTERM);
bool stop_server = false;
client_data* users = new client_data[FD_LIMIT];
bool timeout = false;
alarm(TIMESLOT);
while (!stop_server) {
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if ( (number < 0) && (errno != EINTR)) {
puts("epoll failure");
break;
}
for (int i = 0; i < number; i++) {
int sockfd = events[i].data.fd;
if (sockfd == listenfd) {
struct sockaddr_in client_address;
socklen_t client_addlength = sizeof(client_address);
int connfd = accept(listenfd, (struct sockaddr*)&client_address, &client_addlength);
addfd(epollfd, connfd);
users[connfd].address = client_address;
users[connfd].sockfd = connfd;
util_timer* timer = new util_timer;
timer->user_data = &users[connfd];
timer->cb_func = cb_func;
time_t cur = time(NULL);
timer->expire = cur + 3 * TIMESLOT;
users[connfd].timer = timer;
timer_lst.add_timer(timer);
}
else if ( (sockfd == pipefd[0]) && (events[i].events & EPOLLIN)) {
int sig;
char signals[1024];
ret = recv(pipefd[0], signals, sizeof(signals), 0);
if (ret == -1) {
continue;
}
else if (ret == 0) {
continue;
}
else {
for (int j = 0; j < ret; j++) {
switch(signals[j])
{
case SIGALRM:
{
timeout = true;
break;
}
case SIGTERM:
{
stop_server = true;
}
}
}
}
}
else if (events[i].events & EPOLLIN) {
memset(users[sockfd].buf, '\0', BUFFER_SIZE);
ret = recv(sockfd, users[sockfd].buf, BUFFER_SIZE - 1, 0);
util_timer* timer = users[sockfd].timer;
if (ret < 0) {
if (errno != EAGAIN) {
cb_func(&users[sockfd]);
if (timer) {
timer_lst.del_timer(timer);
}
}
}
else if (ret == 0) {
cb_func(&users[sockfd]);
if (timer) {
timer_lst.del_timer(timer);
}
}
else {
printf("get %d bytes of client data %s from %d\n", ret, users[sockfd].buf, sockfd);
if (timer) {
time_t cur = time(NULL);
timer->expire = cur + 3 * TIMESLOT;
printf("adjust timer once\n");
/* 调整timer在链表中的位置 */
util_timer* tmp = timer->next;
timer->next->prev = timer->prev;
timer->prev->next = timer->next;
bool isLast = true;
while (tmp->next) {
if (timer->expire < tmp->expire) {
timer->next = tmp;
timer->prev = tmp->prev;
tmp->prev->next = timer;
tmp->prev = timer;
isLast = false;
break;
}
tmp = tmp->next;
}
if (isLast) {
timer->next = tmp;
timer->prev = tmp->prev;
tmp->prev->next = timer;
tmp->prev = timer;
}
}
else {
// other
}
}
}
}
if (timeout) {
timer_handler();
timeout = false;
}
}
close(listenfd);
close(pipefd[1]);
close(pipefd[0]);
delete [] users;
return 0;
}高性能定时器
时间轮
模拟时钟,每隔一段时间指针就想下一个槽转动,每个槽都有一个指向定时器链表的指针,每条链表上的定时器具有相同的特征:它们的定时时间相差 N * si,其中 N 是槽的个数,si 是槽之间的时间间隔。时间轮正是利用这个关系将定时器散列到不同的链表中。假如现在指针指向槽 cs,我们要添加一个定时时间为 ti 的定时器,则该定时器将被插入槽 ts = (cs + (ti / si)) % N 对应的链表中
对时间轮而言,要提高定时精度,就要使 si 值足够小;要提高执行效率,则要求 N 值足够大
// time_wheel_timer.h
#ifndef TIME_WHEEL_TIMER
#define TIME_WHEEL_TIMER
#include <time.h>
#include <netinet/in.h>
#include <stdio.h>
#define BUFFER_SIZE 64
class tw_timer;
struct client_data {
sockaddr_in address;
int sockfd;
char buf[BUFFER_SIZE];
tw_timer* timer;
};
class tw_timer {
public:
tw_timer(int rot, int ts) : next(nullptr), prev(nullptr), rotation(rot), time_slot(ts) {}
public:
tw_timer* next;
tw_timer* prev;
int rotation;
int time_slot;
void (*cb_func)(client_data*);
client_data* user_data;
};
class time_wheel {
public:
time_wheel() : cur_slot(0)
{
for (int i = 0; i < N; ++i) {
slots[i] = nullptr;
}
}
~time_wheel() {
for (int i = 0; i < N; ++i) {
tw_timer* tmp = slots[i];
while (tmp) {
slots[i] = tmp->next;
delete tmp;
tmp = slots[i];
}
}
}
tw_timer* add_timer(int timeout) {
if (timeout < 0) {
return nullptr;
}
int ticks = 0;
if (timeout < SI) {
ticks = 1;
}
else {
ticks = timeout / SI;
}
int rotation = ticks / N;
// 算上偏移量
int ts = (cur_slot + (ticks % N)) % N;
tw_timer* timer = new tw_timer(rotation, ts);
if (!slots[ts]) {
printf("add timer, rotation is %d, ts is %d, cur_slot is %d\n", rotation, ts, cur_slot);
slots[ts] = timer;
}
else {
timer->next = slots[ts];
slots[ts]->prev = timer;
slots[ts] = timer;
}
return timer;
}
void del_timer(tw_timer* timer) {
if (!timer) {
return;
}
int ts = timer->time_slot;
if (timer == slots[ts]) {
slots[ts] = slots[ts]->next;
if (slots[ts]) {
slots[ts]->prev = nullptr;
}
delete timer;
}
else {
timer->prev->next = timer->next;
if (timer->next) {
timer->next->prev = timer->prev;
}
delete timer;
}
}
void tick() {
tw_timer* tmp = slots[cur_slot];
printf("current slot is %d\n", cur_slot);
while (tmp) {
printf("tick timer once\n");
if (tmp->rotation > 0) {
--(tmp->rotation);
tmp = tmp->next;
}
else {
tmp->cb_func(tmp->user_data);
if (tmp == slots[cur_slot]) {
printf("delete header in cur_slot\n");
slots[cur_slot] = tmp->next;
delete tmp;
if (slots[cur_slot]) {
slots[cur_slot]->prev = nullptr;
}
tmp = slots[cur_slot];
}
else {
tmp->prev->next = tmp->next;
if (tmp->next) {
tmp->next->prev = tmp->prev;
}
tw_timer* tmp2 = tmp->next;
delete tmp;
tmp = tmp2;
}
}
}
cur_slot = (++cur_slot) % N;
}
private:
static const int N = 60;
static const int SI = 1;
tw_timer* slots[N];
int cur_slot;
};
#endif#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <unistd.h>
#include <stdio.h>
#include <arpa/inet.h>
#include <string.h>
#include <stdlib.h>
#include <errno.h>
#include <assert.h>
#include <sys/epoll.h>
#include <fcntl.h>
#include <signal.h>
#include "time_wheel_timer.h"
#define FD_LIMIT 65535
#define MAX_EVENT_NUMBER 1024
#define TIMESLOT 1
static int pipefd[2];
static time_wheel tw;
static int epollfd = 0;
int setnonblocking(int fd) {
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
void addfd(int epollfd, int fd) {
epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN | EPOLLET;
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}
void sig_handler(int sig) {
int save_errno = errno;
int msg = sig;
send(pipefd[1], (char*)&msg, 1, 0);
errno = save_errno;
}
void addsig(int sig) {
struct sigaction sa;
sa.sa_handler = sig_handler;
sa.sa_flags |= SA_RESTART;
sigfillset(&sa.sa_mask);
assert(sigaction(sig, &sa, NULL) != -1);
}
void timer_handler() {
tw.tick();
alarm(TIMESLOT);
}
void cb_func(client_data* user_data) {
epoll_ctl(epollfd, EPOLL_CTL_DEL, user_data->sockfd, 0);
assert(user_data);
close(user_data->sockfd);
printf("closee fd %d\n", user_data->sockfd);
}
int main(int argc, char** argv) {
if (argc <= 2) {
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
ret = listen(listenfd, 5);
epoll_event events[MAX_EVENT_NUMBER];
epollfd = epoll_create(5);
assert(epollfd != -1);
addfd(epollfd, listenfd);
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, pipefd);
assert(ret != -1);
setnonblocking(pipefd[1]);
addfd(epollfd, pipefd[0]);
addsig(SIGALRM);
addsig(SIGTERM);
bool stop_server = false;
client_data* users = new client_data[FD_LIMIT];
bool timeout = false;
alarm(TIMESLOT);
while (!stop_server) {
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if ( (number < 0) && (errno != EINTR)) {
puts("epoll failure");
break;
}
for (int i = 0; i < number; ++i) {
int sockfd = events[i].data.fd;
if (sockfd == listenfd) {
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof(client_address);
int connfd = accept(listenfd, (struct sockaddr*)&client_address, &client_addrlength);
addfd(epollfd, connfd);
users[connfd].address = client_address;
users[connfd].sockfd = connfd;
// 注意这里的超时时间是相对时间而不是绝对时间,成员方法会计算偏移量的
tw_timer* timer = tw.add_timer(20 * TIMESLOT);
timer->user_data = &users[connfd];
timer->cb_func = cb_func;
users[connfd].timer = timer;
}
else if ( (sockfd == pipefd[0]) && (events[i].events & EPOLLIN)) {
int sig;
char signals[1024];
ret = recv(pipefd[0], signals, sizeof(signals), 0);
if (ret == -1) {
// handle the error
continue;
}
else if (ret == 0) {
continue;
}
else {
for (int j = 0; j < ret; ++j) {
switch(signals[j])
{
case SIGALRM:
{
timeout = true;
break;
}
case SIGTERM:
{
stop_server = true;
}
}
} // for : ret
}
}
else if (events[i].events & EPOLLIN) {
memset(users[sockfd].buf, '\0', BUFFER_SIZE);
ret = recv(sockfd, users[sockfd].buf, BUFFER_SIZE - 1, 0);
tw_timer* timer = users[sockfd].timer;
if (ret < 0) {
if (errno != EAGAIN) {
cb_func(&users[sockfd]);
if (timer) {
tw.del_timer(timer);
}
}
}
else if (ret == 0) {
cb_func(&users[sockfd]);
if (timer) {
tw.del_timer(timer);
}
}
else { // 如果某个客户连接上有数据可读
printf("get %d bytes of client data %s from %d\n", ret, users[sockfd].buf, sockfd);
if (timer) {
// 延长超时时间(先删除原来的,再添加新的)
users[sockfd].timer = nullptr;
tw.del_timer(timer);
tw_timer* new_timer = tw.add_timer(20 * TIMESLOT);
new_timer->user_data = &users[sockfd];
new_timer->cb_func = cb_func;
users[sockfd].timer = new_timer;
}
}
}
} // for : number
if (timeout) {
timer_handler();
timeout = false;
}
}
close(listenfd);
close(pipefd[1]);
close(pipefd[0]);
delete [] users;
return 0;
}工作模式:时间轮指针按固定周期转动,当有客户连接时,将其添加到对应的位置。若规定时间内客户没有响应,则断开客户连接;若客户响应,则重设客户的超时时间(相对时间)
时间堆
使用另一种思路:将所有定时器中超时时间最小的一个定时器的超时值作为心搏间隔。这样,一旦心搏函数 tick 被调用,超时时间最小的定时器必然到期,我们就可以在 tick 函数处理该定时器。然后再从剩余的定时器中找出时间最小的一个,并将这段最小时间设置为下一次心搏间隔。
最小堆很适合处理这种定时方案
// min_heap.h
#ifndef MIN_HEAP
#define MIN_HEAP
#include <iostream>
#include <netinet/in.h>
#include <time.h>
using std::exception;
#define BUFFER_SIZE 64
class heap_timer;
struct client_data {
sockaddr_in address;
int sockfd;
char buf[BUFFER_SIZE];
heap_timer* timer;
};
class heap_timer {
public:
heap_timer(int delay) : expire(time(NULL) + delay) {}
public:
time_t expire;
void (*cb_func)(client_data*);
client_data* user_data;
};
class time_heap {
public:
time_heap(int cap) : capacity(cap), cur_size(0)
{
array = new heap_timer* [capacity];
if (!array) {
throw std::exception();
}
for (int i = 0; i < capacity; ++i) {
array[i] = nullptr;
}
}
time_heap(heap_timer** init_array, int size, int cap) : cur_size(size), capacity(cap)
{
if (cap < size) {
throw std::exception();
}
array = new heap_timer* [capacity];
if (!array) {
throw std::exception();
}
for (int i = 0; i < capacity; ++i) {
if (i < size) array[i] = init_array[i];
else array[i] = nullptr;
}
/* 对数组中第 0 ~ [(cur_size - 1) / 2] 个元素执行下滤操作 */
for (int i = (cur_size - 1) / 2; i >= 0; --i) {
percolate_down(i);
}
}
~time_heap() {
for (int i = 0; i < cur_size; ++i) {
delete array[i];
}
delete [] array;
}
public:
void add_timer(heap_timer* timer) {
if (!timer) {
return;
}
if (cur_size >= capacity) {
resize();
}
int hole = cur_size++;
int parent = 0;
while (hole > 0) {
parent = (hole - 1) / 2;
if (array[parent]->expire <= timer->expire) {
break;
}
array[hole] = timer;
hole = parent;
}
}
void del_timer(heap_timer* timer) {
if (!timer) {
return;
}
timer->cb_func = nullptr; // 延迟销毁
}
heap_timer* top() const {
if (empty()) {
return nullptr;
}
return array[0];
}
void pop_timer() {
if (empty()) {
return;
}
if (array[0]) {
delete array[0];
array[0] = array[--cur_size];
percolate_down(0);
}
}
void tick() {
heap_timer* tmp = top();
time_t cur = time(NULL);
while (!empty()) {
if (!tmp) break;
if (tmp->expire > cur) {
break;
}
if (array[0]->cb_func) {
array[0]->cb_func(array[0]->user_data);
}
pop_timer();
tmp = top();
}
}
bool empty() const { return cur_size == 0; }
private:
void percolate_down(int hole) {
heap_timer* temp = array[hole];
int child;
for (child = 0; hole * 2 + 1 < cur_size; hole = child) {
child = hole * 2 + 1; // 左儿子
if (child + 1 < cur_size && array[child + 1]->expire < array[child]->expire) {
++child;
}
if (array[child]->expire < temp->expire) { // 注意这里是temp->expire, 我们没有作实际的交换
array[hole] = array[child];
}
else break;
}
array[hole] = temp;
}
// 两倍扩容
void resize() {
heap_timer** temp = new heap_timer* [2 * capacity];
if (!temp) {
throw std::exception();
}
for (int i = 0; i < 2 * capacity; ++i) {
if (i < cur_size) temp[i] = array[i];
else temp[i] = nullptr;
}
delete [] array;
array = temp;
}
private:
heap_timer** array;
int capacity;
int cur_size;
};
#endif多进程编程
fork 系统调用
Linux 下创建新进程的系统调用:
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);该函数的每次调用都返回两次,在父进程中返回的是子进程的 PID ,在子进程中则返回 0
fork 函数复制当前进程,在内核进程表中创建一个新的进程表项,新进程的 PPID 被设置成原进程的 PID,信号位图被清除(原进程设置的信号处理函数不再对新进程起作用);子进程的代码与父进程完全相同,同时它还会复制父进程的数据(堆、栈和静态数据),因此,如果我们在程序中分配了大量内存,那么使用 fork 时应当十分谨慎,尽量避免没必要的内存分配和数据复制;创建子进程后,父进程中打开的文件描述符默认在子进程中也是打开的,且文件描述符的引用计数加1
处理僵尸进程
当子进程结束运行时,内核不会立即释放该进程的进程表表项,以满足父进程后续对该子进程退出信息的查询(如果父进程还在运行)
- 在子进程结束运行之后,父进程读取其退出状态之前,我们称该子进程处于僵尸态
- 另一种使子进程进入僵尸态的情况是:父进程结束或者异常终止,而子进程继续运行。此时由
init进程接管该子进程
如果父进程没有正确地处理子进程的返回信息,子进程都将停留在僵尸态,并占据着内核资源
因此需要等待子进程的结束并获取子进程的返回信息:
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int* stat_loc);
pid_t waitpid(pid_t pid, int* stat_loc, int option);wait 函数将阻塞进程,直到该进程的某个子进程结束运行为止,因此不少服务器程序所期望的,而 waitpid 解决了这个问题
pid: 等待指定 pid 的子进程,若为 -1,就等待任意一个进程stat_loc: 保存子进程的退出信息,可以设置为 NULLoption: 控制waitpid函数的行为,该参数最常用的取值是 WNOHANG ,它使得waitpid是非阻塞的,如果 pid 指定的目标子进程还没有结束或意外终止,则waitpid立即返回0,如果目标子进程确实正常退出了,则返回子进程 pid,调用失败时返回 -1 并设置 errno
当子进程结束后会发出 SIGCHLD 信号,此时我们就可以在信号处理函数中调用 waitpid 函数以 “彻底结束” 一个子进程
static void handle_child(int sig) {
pid_t pid;
int stat;
while ( (pid = waitpid(-1, &stat, WNOHANG)) > 0) {
/* 对结束的子进程进行善后处理 */
}
}管道(父子进程间通信)
管道能在父、子进程间传递数据,利用的是 fork 调用之后两个管道文件描述符都保持打开,一对这样的文件描述符只能保证父、子进程间一个方向的数据传输,父进程和子进程都必须有一个关闭 fd[0] ,另一个关闭 fd[1]
显然,如果要实现父、子进程之间的双向数据传输,就必须使用两个管道,利用 socketpair .不过,管道只能用于有关联的两个进程间的通信,但是有一种特殊的管道 (FIFO 管道)也能用于无关联进程之间的通信
信号量
信号量(Semaphore):有时被称为信号灯,是在多线程环境下使用的一种设施,可以用来保证两个或多个关键代码段不被并发调用。在进入一个关键代码段之前,线程必须获取一个信号量,一旦该关键代码完成了,那么该线程必须释放信号量。其它想进入该关键代码段的线程必须等待直到第一个线程释放信号量
共享内存
共享内存是最高效的 IPC 机制,因为它不涉及进程之前的任何数据传输,通常和其他进程间通信方式一起使用
shmget 系统调用
shmget 系统调用创建一段新的共享内存,或者获取一段已经存在的共享内存:
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);key 参数是一个键值,用来标识一段全局唯一的共享内存
size 参数指定共享内存的大小,单位是字节,如果是获取已经存在的共享内存,可以设为0
shmflg 参数的使用与含义与 semget 系统调用的 sem_flags 参数相同,不过它支持两个额外的标志 SHM_HUGETLB 和 SHM_NORESERVE :
- SHM_HUGETLB : 系统将使用”大页面”来为共享内存分配空间
- SHM_NORESERVE : 不为共享内存保留交换分区,这样,当物理内存不足的时候,对该共享内存执行写操作将触发 SIGSEGV 信号
成功时返回一个正整数值,它是共享内存的标识符,失败时返回-1并设置 errno
shmat 和 shmdt 系统调用
共享内存被创建/获取之后,我们不能立即访问它,而是需要先将它关联到进程的地址空间中。使用完共享内存之后,我们也需要将它从进程地址空间中分离。
#include <sys/shm.h>
void* shmat(int shm_id, const void* shm_addr, int shmflg);
int shmdt(const void* shm_addr);shm_id 参数是由 shmget 调用返回的共享内存标识符
shm_addr 参数指定将共享内存关联到进程的哪块地址空间(若为 NULL ,则被关联的地址由操作系统选择)
shmflg 参数限制了对共享内存的相关操作
shmctl 系统调用
shmctl 系统调用控制共享内存的某些属性。定义如下:
#include <sys/shm.h>
// 成功时的返回值取决于 command 参数
int shmctl(int shm_id, int command, struct shmid_ds* buf);共享内存的 POSIX 方法
Linux 提供了另外一种利用 mmap 在无关进程之间共享内存的方式,这种方式无须任何文件的支持,但它需要先使用如下函数来创建或打开一个 POSIX 共享内存对象
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
int shm_open(const char* name, int oflag, mode_t mode);shm_open 的使用方法与 open 系统调用完全相同
name 参数指定要创建 / 打开的共享内存对象
oflag 参数指定创建方式:
- O_RDONLY:以只读方式打开共享内存对象
- O_RDWR:以可读、可写方式打开共享内存对象
- O_CREAT:如果共享内存对象不存在,则创建之
- O_EXCL:和 O_CREAT 一起使用,如果由
name指定的共享内存对象已经存在,则shm_open调用返回错误,否则就创建一个新的共享内存对象
shm_open 调用成功时返回一个文件描述符,该文件描述符可用于后续的 mmap 调用,从而将共享内存关联到调用进程。失败时返回 -1, 并设置 errno
同样,由 shm_open 创建的共享内存对象使用完之后也需要被删除
int shm_unlink(const char* name);该参数将 name 参数指定的共享内存对象标记为等待删除,当所有使用该共享内存对象的进程都使用 mummap 将它从进程中分离之后,系统将销毁这个共享内存所占据的资源(注意:如果代码中使用了上述 POSIX 共享内存函数,则编译的时候需要指定链接选项 -lrt )
使用共享内存的聊天室服务器程序
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <signal.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/shm.h>
#define USER_LIMIT 5
#define BUFFER_SIZE 1024
#define FD_LIMIT 65535
#define MAX_EVENT_NUMBER 1024
#define PROCESS_LIMIT 65536
struct client_data {
sockaddr_in address;
int connfd;
pid_t pid;
int pipefd[2];
};
static const char* shm_name = "/my_shm";
int sig_pipefd[2];
int epollfd;
int listenfd;
int shmfd;
char* share_mem = nullptr;
client_data* users = nullptr;
int* sub_process = nullptr;
int user_count = 0;
bool stop_child = false;
int setnonblocking(int fd) {
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
void addfd(int epollfd, int fd) {
epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN | EPOLLET;
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}
void sig_handler(int sig) {
int save_errno = errno;
int msg = sig;
send(sig_pipefd[1], (char*)&msg, 1, 0);
errno = save_errno;
}
void addsig(int sig, void(*handler)(int), bool restart = true) {
struct sigaction sa;
memset(&sa, '\0', sizeof(sa));
sa.sa_handler = handler;
if (restart) {
sa.sa_flags |= SA_RESTART;
}
sigfillset(&sa.sa_mask);
assert(sigaction(sig, &sa, NULL) != -1);
}
void del_resource() {
close(sig_pipefd[0]);
close(sig_pipefd[1]);
close(listenfd);
close(epollfd);
shm_unlink(shm_name);
delete [] users;
delete [] sub_process;
}
void child_term_handler(int sig) {
stop_child = true;
}
int run_child(int idx, client_data* users, char* share_mem) {
epoll_event events[MAX_EVENT_NUMBER];
int child_epollfd = epoll_create(5);
assert(child_epollfd != -1);
int connfd = users[idx].connfd;
addfd(child_epollfd, connfd);
int pipefd = users[idx].pipefd[1];
addfd(child_epollfd, pipefd);
int ret;
addsig(SIGTERM, child_term_handler, false);
while (!stop_child) {
int number = epoll_wait(child_epollfd, events, MAX_EVENT_NUMBER, -1);
if ( (number < 0) && (errno != EINTR)) {
puts("epoll failure");
break;
}
for (int i = 0; i < number; i++) {
int sockfd = events[i].data.fd;
if ( (sockfd == connfd) && (events[i].events & EPOLLIN)) {
memset(share_mem + idx * BUFFER_SIZE, '\0', BUFFER_SIZE);
ret = recv(connfd, share_mem + idx * BUFFER_SIZE, BUFFER_SIZE - 1, 0);
if (ret < 0) {
if (errno != EAGAIN) {
stop_child = true;
}
}
else if (ret == 0) {
stop_child = true;
}
else {
send(pipefd, (char*)&idx, sizeof(idx), 0);
}
}
// 子进程接收父进程通过管道发来的信息
else if ( (sockfd == pipefd) && (events[i].events & EPOLLIN)) {
int client = 0;
ret = recv(sockfd, (char*)&client, sizeof(client), 0);
if (ret < 0) {
if (errno != EAGAIN) {
stop_child = true;
}
}
else if (ret == 0) {
stop_child = true;
}
else {
send(connfd, share_mem + client * BUFFER_SIZE, BUFFER_SIZE, 0);
}
}
}
}
close(connfd);
close(pipefd);
close(child_epollfd);
return 0;
}
int main(int argc, char* argv[]) {
if (argc <= 2) {
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
inet_pton(AF_INET, ip, &address.sin_addr);
listenfd = socket(PF_INET, SOCK_STREAM, 0);
ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
user_count = 0;
users = new client_data [USER_LIMIT + 1];
sub_process = new int [PROCESS_LIMIT];
for (int i = 0; i < PROCESS_LIMIT; ++i) {
sub_process[i] = -1;
}
epoll_event events[MAX_EVENT_NUMBER];
epollfd = epoll_create(5);
assert(epollfd != -1);
addfd(epollfd, listenfd);
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, sig_pipefd);
assert(ret != -1);
setnonblocking(sig_pipefd[1]);
addfd(epollfd, sig_pipefd[0]);
addsig(SIGCHLD, sig_handler);
addsig(SIGTERM, sig_handler);
addsig(SIGINT, sig_handler);
addsig(SIGPIPE, SIG_IGN);
bool stop_server = false;
bool terminate = false;
shmfd = shm_open(shm_name, O_CREAT | O_RDWR, 0666);
assert(shmfd != -1);
ret = ftruncate(shmfd, USER_LIMIT * BUFFER_SIZE);
assert(ret != -1);
share_mem = (char*)mmap(NULL, USER_LIMIT * BUFFER_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, shmfd, 0);
assert(share_mem != MAP_FAILED);
close(shmfd);
while (!stop_server) {
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if ( (number < 0) && (errno != EINTR) ) {
puts("epoll failure");
break;
}
for (int i = 0; i < number; i++) {
int sockfd = events[i].data.fd;
if (sockfd == listenfd) {
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof(client_address);
int connfd = accept(listenfd, (struct sockaddr*)&client_address, &client_addrlength);
if (connfd < 0) {
printf("errno is: %d\n", errno);
continue;
}
if (user_count >= USER_LIMIT) {
const char* info = "too many users\n";
printf("%s", info);
send(connfd, info, strlen(info), 0); // 给想连接的客户发送信息
close(connfd);
continue;
}
users[user_count].address = client_address;
users[user_count].connfd = connfd;
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, users[user_count].pipefd);
assert(ret != -1);
pid_t pid = fork();
if (pid < 0) {
close(connfd);
continue;
}
else if (pid == 0) {
close(epollfd);
close(listenfd);
close(users[user_count].pipefd[0]);
close(sig_pipefd[0]);
close(sig_pipefd[1]);
run_child(user_count, users, share_mem);
munmap((void*)share_mem, USER_LIMIT * BUFFER_SIZE); // 注意要释放内存
exit(0);
}
else {
close(connfd);
close(users[user_count].pipefd[1]);
addfd(epollfd, users[user_count].pipefd[0]);
users[user_count].pid = pid;
sub_process[pid] = user_count;
user_count++;
}
}
else if ( (sockfd == sig_pipefd[0]) && (events[i].events & EPOLLIN)) {
int sig;
char signals[1024];
ret = recv(sig_pipefd[0], signals, sizeof(signals), 0);
if (ret == -1) {
continue;
}
else if (ret == 0) {
continue;
}
else {
for (int j = 0; j < ret; j++) {
switch(signals[j]) {
case SIGCHLD:
{
pid_t pid;
int stat;
while ( (pid = waitpid(-1, &stat, WNOHANG)) > 0) {
int del_user = sub_process[pid];
sub_process[pid] = -1;
if ( (del_user < 0) || (del_user > USER_LIMIT)) {
continue;
}
epoll_ctl(epollfd, EPOLL_CTL_DEL, users[del_user].pipefd[0], 0);
close(users[del_user].pipefd[0]);
users[del_user] = users[--user_count];
sub_process[users[del_user].pid] = del_user;
}
if (terminate && user_count == 0) {
stop_server = true;
}
break;
}
case SIGTERM:
case SIGINT:
{
puts("kill all the child now");
if (user_count == 0) {
stop_server = true;
break;
}
for (int k = 0; k < user_count; ++k) {
int pid = users[k].pid;
kill(pid, SIGTERM);
}
terminate = true;
break;
}
default:
{
break;
}
}
}
}
}
else if (events[i].events & EPOLLIN) {
int child = 0;
ret = recv(sockfd, (char*)&child, sizeof(child), 0); // 这里没有传递实际的数据,而只是一个user_count下标,借此找到要读的共享内存段
puts("read data from child accross pipe");
if (ret == -1) {
continue;
}
else if (ret == 0) {
continue;
}
else {
for (int j = 0; j < user_count; ++j) {
if (users[j].pipefd[0] != sockfd) {
puts("send data to child accross pipe");
send(users[j].pipefd[0], (char*)&child, sizeof(child), 0);
}
}
}
}
}
}
del_resource();
return 0;
}
消息队列
消息队列是在两个进程之间传递二进制块数据的一种简单有效的方式。每个数据块都有一个特定的类型,接收方可以根据类型来有选择的接收数据,而不一定像管道和命名管道那样必须以先进先出的方式接收数据
msgget 系统调用
创建一个消息队列,或者获取一个已有的消息队列。定义如下:
#include <sys/msg.h>
int msgget(key_t key, int msgflg);key 参数是一个键值,用来标识一个全局唯一的消息队列
msgflg 参数的使用含义与 semget 系统调用的 sem_flags 参数相同
msgsnd 系统调用
把一条消息添加到消息队列中。定义如下:
#include <sys/msg.h>
// 成功时返回0, 失败时返回 -1 并设置 errno
int msgsnd(int msqid, const void* msg_ptr, size_t msg_sz, int msgflg);msqid 参数是由 msgget 调用返回的消息队列标识符
msg_ptr 参数指向一个准备发送的消息,消息必须被定义为如下类型:
struct msgbuf {
long mtype; /* 消息类型, 必须是一个正整数 */
char mtext[512]; /* 消息数据 */
};msgflg 参数控制 msgsnd 的行为,它通常仅支持 IPC_NOWAIT 标志,即以非阻塞的方式发送消息。默认情况下,发送消息时如果消息队列满了,则 msgsnd 将阻塞。若此标志被指定,这立即返回并设置 errno 为 EAGAIN
处于阻塞状态的 msgsnd 调用可能被如下两种异常情况所中断:
- 消息队列被移除
- 程序接受到信号
msgrcv 系统调用
从消息队列中获取消息。定义如下:
#include <sys/msg.h>
// 成功时返回0, 失败则返回 -1 并设置 errno
int msgrcv(int msqid, void* msg_ptr, size_t msg_sz, long int msgtype, int msgflg);msgctl 系统调用
控制消息队列的某些属性。定义如下:
#include <sys/msg.h>
// msgctl 成功时的返回值取决于command 参数
int msgctl(int msqid, int command, struct msqid_ds* buf);多线程编程
线程是程序中完成一个独立任务的完整执行序列,即一个可调度的实体。根据运行环境和调度者的身份,线程可分为内核线程和用户线程 。当进程的一个内核线程获得 CPU 的使用权时,它就加载并运行一个用户线程。
POSIX 线程 API
#include <pthread.h>
// 1. 创建一个线程
// pthread_t 是 unsigned long int 类型
// attr 设置线程属性, 一般为 NULL
// start_routine 是函数指针, 指向线程将要执行的任务
// arg 是函数参数
int pthread_create(pthread_t* thread, const pthread_attr_t* attr,
void* (*start_routine)(void*), void* arg);
// 2.线程结束(执行完之后不会反回到调用者, 而且永远不会失败)
void pthread_exit(void* retval);
// 3.等待其它线程结束
int pthread_join(pthread_t thread, void** retval);
// 4.异常终止一个线程
int pthread_cancel(pthread_t thread);一个用户可以打开的线程数量不能超过软资源限制。此外,系统上所有用户能创建的线程总数也不得超过
/proc/sys/kernel/threads-max内核参数所定义的值线程函数在结束时最好调用此函数,以确保安全、干净地退出
注意这里传入的不是指针
该函数成功时返回0,失败则返回错误码
POSIX 信号量
三种专门用于线程同步的机制:POSIX信号量、互斥量和条件变量
#include <semaphore.h>
// 初始化信号量
// 1. sem_t 变量
// 2. pshared 为0表示这个信号量是当前进程的局部信号量, 否则该信号量可以在多个进程之间共享
// 3. value 指定信号量初始值
int sem_init(sem_t* sem, int pshared, unsigned int value);
// 销毁信号量
int sem_destroy(sem_t* sem);
// 以原子操作的方式将信号量的值减一。 减完后信号量的值若小于0,就等待至信号量大于等于0
int sem_wait(sem_t* sem);
// 始终立即返回, 当信号量为0时返回-1并设置errno
int sem_trywait(sem_t* sem);
// 原子地将信号量加一
int sem_post(sem_t* sem);互斥锁基础 API
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t* mutex, const pthread_mutexattr_t* mutexattr);
int pthread_mutex_destroy(pthread_mutex_t* mutex);
int pthread_mutex_lock(pthread_mutex_t* mutex);
int pthread_mutex_trylock(pthread_mutex_t* mutex);
int pthread_mutex_unlock(pthread_mutex_t* mutex);条件变量
#include <pthread.h>
int pthread_cond_init(pthread_cond_t* cond, const pthread_condattr_t* cond_attr);
int pthread_cond_destroy(pthread_cond_t* cond);
// 相当于c++的 notify_all()
int pthread_cond_broadcast(pthread_cond_t* cond);
// 相当于c++的 notify_one()
int pthread_cond_signal(pthread_cond_t* cond);
int pthread_cond_wait(pthread_cond_t* cond, pthread_mutex_t* mutex);进程和线程
多线程环境下,子进程只拥有一个执行线程,它是调用 fork 的那个线程的完整复制。并且子进程将自动继承父进程中互斥锁(条件变量与之类似)的状态。这就引起了一个问题:子进程可能不清楚从父进程继承而来的互斥锁的具体状态。这个互斥锁可能被加锁了,但并不是由调用 fork 函数的那个线程锁住的,而是由其它线程锁住的。如果是这种情况,则子进程若再次对该互斥锁执行加锁操作就会导致死锁

