
Nginx自旋锁
概念
自旋锁是一种基本的同步原语,用于实现多线程编程中的互斥访问控制。它通过循环自旋的方式等待获取锁,而不是将线程阻塞挂起。当自旋锁处于被占用状态时,线程会一直自旋等待直到锁可用。
以下是自旋锁的一般特征和使用方式:
- 特征:
- 互斥性:自旋锁用于保护临界区,确保同时只有一个线程可以进入临界区执行操作,从而避免竞争条件和数据不一致性。
- 忙等待:当自旋锁已经被其他线程占用时,等待的线程会循环自旋(忙等待)直到获取到锁。
- 线程占用:一旦一个线程获取到自旋锁,其他线程必须等待该线程释放锁才能获取锁。
- 简单快速:相对于一些复杂的同步原语,自旋锁的实现通常较为简单且执行速度较快。
- 使用方式:
- 初始化:在使用自旋锁之前,需要对其进行初始化。
- 获取锁:当线程需要进入临界区时,调用获取锁的操作。如果锁已经被其他线程占用,则线程会不断自旋等待,直到获取到锁为止。
- 释放锁:当线程完成临界区的操作后,调用释放锁的操作,将锁标记为可用状态,允许其他线程获取锁。
需要注意的是,自旋锁适用于以下情况:
- 临界区的代码执行时间较短,自旋等待的时间较短,以避免线程阻塞和上下文切换的开销。
- 并发线程数相对较少,以减少线程竞争锁的概率。
然而,自旋锁也存在一些潜在的问题。如果自旋等待时间过长或线程数过多,会导致CPU资源的浪费。此外,自旋锁在单核处理器上没有明显的性能优势,因为只有一个核心可以执行代码。
在实践中,通常可以选择使用更高级别的同步原语,如互斥锁、读写锁或条件变量,以根据具体场景和需求来实现线程同步和互斥控制。
Nginx自旋锁
- 应用场景:线程池实现中从任务队列中取出任务(任务队列是一个静态全局变量)
- 性能优化:在多核
cpu时使用cpu暂停指令,用于让处理器暂停执行并等待一段时间,以降低自旋等待时的功耗和资源消耗。它在多核处理器上可以提供性能优势,尤其在共享资源竞争的情况下。使用yield函数使cpu调度到其他线程
自旋锁加锁
- 使用原子变量
lock表示自旋锁是否被持有(0:未持有,1:持有) - 每次循环判断是否处于未持有状态并使用原子操作
compare and set原子地比较并设置lock为 1,如果设置成功说明当前线程成功获取了锁,直接返回即可 - 如果获取失败,当多核时,根据
spin值暂停cpu一段时间,这里的spin值应该是一个经验值,在nginx中传入为2048,即cpu暂停指令执行1 + 2 + 3 + ... + 12次,之后再重新尝试获取自旋锁 - 最后调用
yield将当前线程调度到其他地方执行void ngx_spinlock(ngx_atomic_t *lock, ngx_atomic_int_t value, ngx_uint_t spin) { #if (NGX_HAVE_ATOMIC_OPS) ngx_uint_t i, n; for ( ;; ) { if (*lock == 0 && ngx_atomic_cmp_set(lock, 0, value)) { return; } if (ngx_ncpu > 1) { for (n = 1; n < spin; n <<= 1) { for (i = 0; i < n; i++) { ngx_cpu_pause(); } if (*lock == 0 && ngx_atomic_cmp_set(lock, 0, value)) { return; } } } ngx_sched_yield(); } #else #if (NGX_THREADS) #error ngx_spinlock() or ngx_atomic_cmp_set() are not defined ! #endif #endif }
自旋锁解锁
- 将
lock变量赋值为0即可#define ngx_unlock(lock) *(lock) = 0
Nginx自旋锁的 C++ 实现
#include <atomic>
#include <thread>
class SpinLock {
public:
void lock(int value = 0, int spin = 2048) {
for (;;) {
if (islocked == 0 && islocked.compare_exchange_strong(value, 1)) {
return;
}
if (ncpu > 1) {
for (int n = 1; n < spin; n <<= 1) {
for (int i = 0; i < n; i++) {
__asm__ ("pause");
}
}
if (islocked == 0 && islocked.compare_exchange_strong(value, 1)) {
return;
}
}
std::this_thread::yield();
}
}
void unlock() { islocked = 0; }
private:
std::atomic<int> islocked {0};
const int ncpu = std::thread::hardware_concurrency();
};自旋锁性能测试
- 用循环加计数器来模拟临界操作,循环次数越多临界区操作的时间就越长
- 观察临界区操作时间增加和线程数增加的情况下自旋锁和互斥锁的性能表现
#include <benchmark/benchmark.h> #include <mutex> #include "spinlock.h" SpinLock spin; std::mutex mtx; static void BM_SpinLock(benchmark::State& state) { for (auto _ : state) { int counter = 0; spin.lock(); for (int i = 0; i < state.range(0); i++) { counter++; } spin.unlock(); } } static void BM_MutexLock(benchmark::State& state) { for (auto _ : state) { int counter = 0; mtx.lock(); for (int i = 0; i < state.range(0); i++) { counter++; } mtx.unlock(); } } BENCHMARK(BM_SpinLock)->Arg(10)->Threads(1)->Threads(2)->Threads(4)->Threads(8)->Threads(16); BENCHMARK(BM_MutexLock)->Arg(10)->Threads(1)->Threads(2)->Threads(4)->Threads(8)->Threads(16); BENCHMARK(BM_SpinLock)->Arg(1000)->Threads(1)->Threads(2)->Threads(4)->Threads(8)->Threads(16); BENCHMARK(BM_MutexLock)->Arg(1000)->Threads(1)->Threads(2)->Threads(4)->Threads(8)->Threads(16); BENCHMARK(BM_SpinLock)->Arg(10000000)->Threads(1)->Threads(2)->Threads(4)->Threads(8)->Threads(16); BENCHMARK(BM_MutexLock)->Arg(10000000)->Threads(1)->Threads(2)->Threads(4)->Threads(8)->Threads(16); BENCHMARK_MAIN();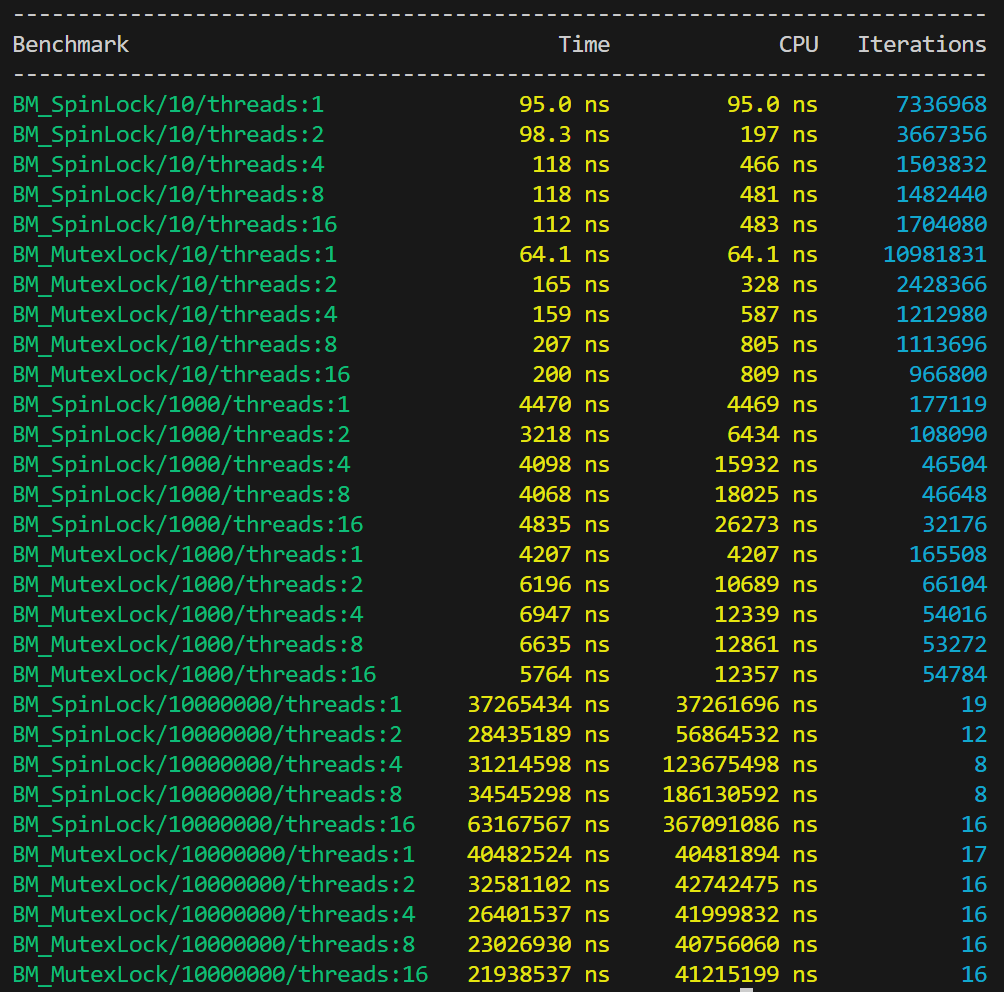
观察测试结果我们可以发现,单线程时自旋锁的性能差,当线程数较少时性能比较好,但线程数多了会影响自旋锁的性能。当临界区操作时间短时,自旋锁性能明显由于互斥锁,但随着临界区操作时间的增长,自旋锁的性能会逐渐降低
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.

